L’algorithme d’apprentissage le plus simple (les $k$ plus proches voisins)#
Commençons par étudier le problème le plus fondamental et représentatif de l’apprentissage automatique, celui de la classification d’objets. Par exemple, pouvoir dire si l’image sur cette photo est celle d’un chien, ou d’un chat. Si on considère de nouveau notre scénario initial, on peut synthétiser la structure du problème de la manière suivante :
- Nous avons à priori une série d’objets existants (des données)
- Chaque objet a des caractéristiques qui le décrivent, ainsi qu’une classe (on parle parfois aussi d’une étiquette, ou label en anglais)
- Il est possible de mesurer la distance qui sépare deux objets (en se basant sur les caractéristiques); cette distance peut être vue aussi comme une mesure de similarité, à quel point les deux objets sont semblables
- Pour un nouvel objet qu’on nous donne, dont on connaît les caractéristiques mais pas la classe (parce que personne nous l’a donnée), nous aimerions la prédire (la classe)
L’algorithme le plus simple pour faire cela est assurément celui des $k$ plus proches voisins ($k$-NN, $k$ Nearest Neighbors). Pour chaque point que l’on désire classifier, il suffit de considérer ses $k$ plus proches voisins (proche, dans la plupart des contextes géométriques, veut dire en terme de la distance euclidienne) et de choisir la classe majoritaire. Notez que cet algorithme pourrait s’appeler également les $k$ voisins les plus semblables, car la distance peut également être interprétée en tant que mesure de similarité. L’applet interactive suivante illustre ce fonctionnement, à l’aide de points rouges et bleus en deux dimensions.
Dans cet exemple :
- Les caractéristiques des points 2D sont leurs coordonnées $x$ et $y$
- Leurs classes sont
rougeoubleu - La distance entre les points est la distance euclidienne
- Les régions en bleu et rouge pâle correspondent à la classification de tout nouveau point ajouté dans cette région (un point apparaît en cliquant)
Pourquoi dit-on que cet algorithme est le plus simple? Parce que contrairement à d’autres algorithmes d’apprentissage que nous verrons plus tard :
- Il y a un seul paramètres qui doit être “appris” : $k$, soit le nombre de voisins consultés;
- Bien qu’il y ait un jeu de données d’entraînement, il n’y a pas de processus d’entraînement, à proprement parler (contrairement à la plupart des algorithmes que nous verrons par la suite): dès qu’on a un ensemble de données étiquetées, l’algorithme est prêt à être utilisé; si on ajoute un nouveau point, il est instantanément classé, en fonction de ses $k$ plus proches voisins
Dans un sens, les données d’entraînement, accompagnées d’un choix de valeur pour $k$, constitue l’algorithme, ou le modèle lui-même.
Le compromis, ou dilemme biais-variance#
Nous allons maintenant introduire deux notions fondamentales en apprentissage automatique, qui vont nous permettre d’en comprendre l’enjeu, ou la difficulté principale.
Le biais d’un modèle est l’erreur qu’il introduit avec ses hypothèses de départ, ce qu’il considère comme étant vrai à priori, avant même de commencer à apprendre. Par exemple, si mon “modèle” du temps estimé pour me rendre au travail est que “ça prend toujours 20 minutes”, alors dans certains cas, il sera en erreur, car il n’aura pas pris en considération le fait qu’il pleut aujourd’hui, ou que c’est le jour du Tour de l’Ile à Montréal. C’est un modèle beaucoup trop général, au point où il est très peu utile, car trop flou.
La variance d’un modèle est l’erreur qui est introduite quand j’essaie de bâtir un modèle à partir de ces exemples particuliers (ces données d’entraînement particulières, que j’ai possiblement obtenu par hasard) plutôt que ceux-là. Il s’agit donc de l’erreur qui correspond aux variations naturelles, ou accidentelles, qu’on observe dans la nature, ce qu’on nomme parfois aussi le bruit. Par exemple, si mon “modèle” du temps estimé pour me rendre au travail est basé sur mes observations d’une semaine particulière, donc : “20 minutes le lundi”, “30 minutes le mardi”, et ainsi de suite, il est très probable que ce modèle colle de trop près à la réalité, et qu’il tente trop de généraliser à partir de ce qui n’est, au fond, que des fluctuations aléatoires (le fait que ça m’a pris 20 minutes pour me rendre au travail lundi passé est assez peu corrélé avec le temps que ça me prendra le lundi suivant, et c’est probablement une erreur de trop vouloir généraliser). Ce modèle est trop spécifique, pas assez général.
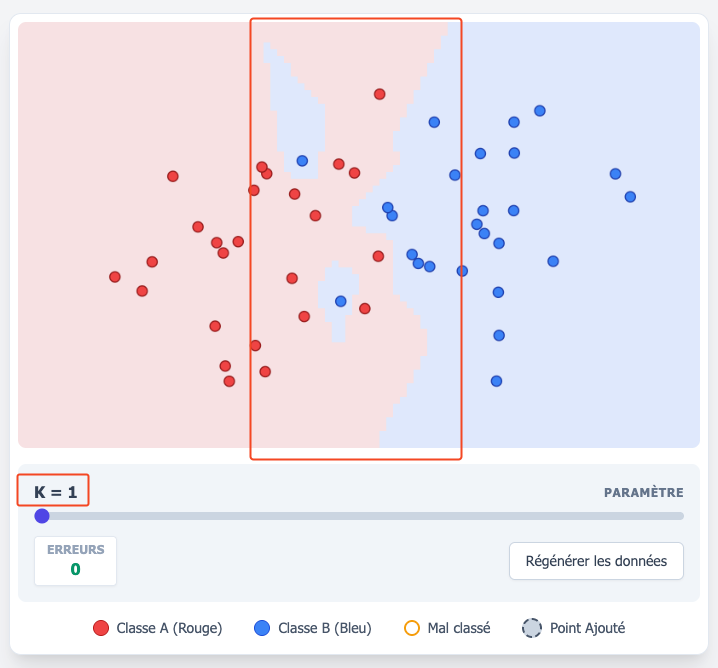
Nous pouvons donc analyser notre algorithme des plus proches voisins à la lumière de ces notions : quand $k$ est petit, la variance du modèle est très élevée, et les particularités individuelles des données (le fait que ce point rouge soit exactement ici, plutôt que là) ont une grande importance. On parle ici de sur-apprentissage (overfitting). Visuellement, on peut constater ceci en considérant que la ligne de décision (l’endroit où la zone rouge pâle du fond devient bleue pâle, et qui marque le classement de tout nouveau point éventuel) est complexe et fragmentée, car elle épouse presque parfaitement les particularités de ce jeu de données particulier, afin d’éviter toute erreur (et d’ailleurs on remarque aussi que cette configuration change complètement, dès qu’on régénère de nouvelles données aléatoires).
À l’inverse, quand $k$ est très grand, c’est le biais qui devient très élevé : le modèle prend en considération un très grand nombre de facteurs (c-à-d de points) pour prendre une décision, et probablement qu’il s’agit d’une généralisation excessive. On parle alors de sous-apprentissage (underfitting). La ligne de décision entre les zones rouges et bleues devient alors plus linéaire, et moins changeante, car elle représente une décision moyenne, plus tolérante aux erreurs potentielles avec les données d’entraînement. Le modèle aurait probablement avantage, dans ce cas, à considérer les données de manière un peu plus spécifique.
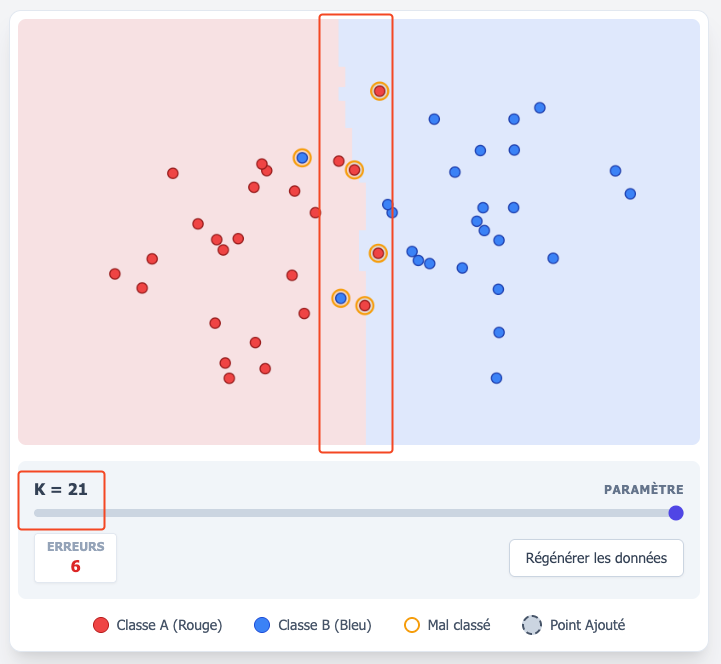
On considère en général que ces deux notions sont l’inverse, l’une de l’autre : quand le biais d’un modèle augmente, sa variance diminue, et vice versa. L’apprentissage automatique constitue donc l’art de trouver un bon compromis entre ces deux extrêmes.

Deux types d’erreur#
Quand on joue avec l’applet interactive ci-haut, et qu’on choisit $k=1$, on remarque que l’erreur est zéro. Ceci est dû au fait que par définition, un point est lui-même inclus dans ses $k$ voisins, donc quand le point est seul, il ne peut y avoir aucune erreur. En augmentant $k$, le nombre d’erreurs augmente généralement. On pourrait imaginer qu’un algorithme qui ne commet aucune erreur est désirable, mais dans le cas de $k$-NN, ce résultat en apparence impressionnant est tout simplement trivial, car il est obtenu par définition. Comme cette erreur est calculée sur le jeu de données correspondant à l’entraînement, on parle alors d’erreur d’entraînement. En apprentissage automatique, il est souvent possible, avec différents algorithmes, de faire en sorte que cette erreur soit très proche de zéro. Pourtant, l’erreur qui nous intéresse réellement est celle calculée à partir d’un autre jeu de données, qui n’a pas participé à l’entraînement du modèle : on parle alors de l’erreur de test. Contrairement à l’erreur d’entraînement, qui est minimisée dans le cas des $k$ plus proches voisins quand $k=1$, l’erreur de test aura tendance à être minimisée à la valeur de $k$ qui correspond au meilleur compromis biais-variance, comme l’illustre ce diagramme :
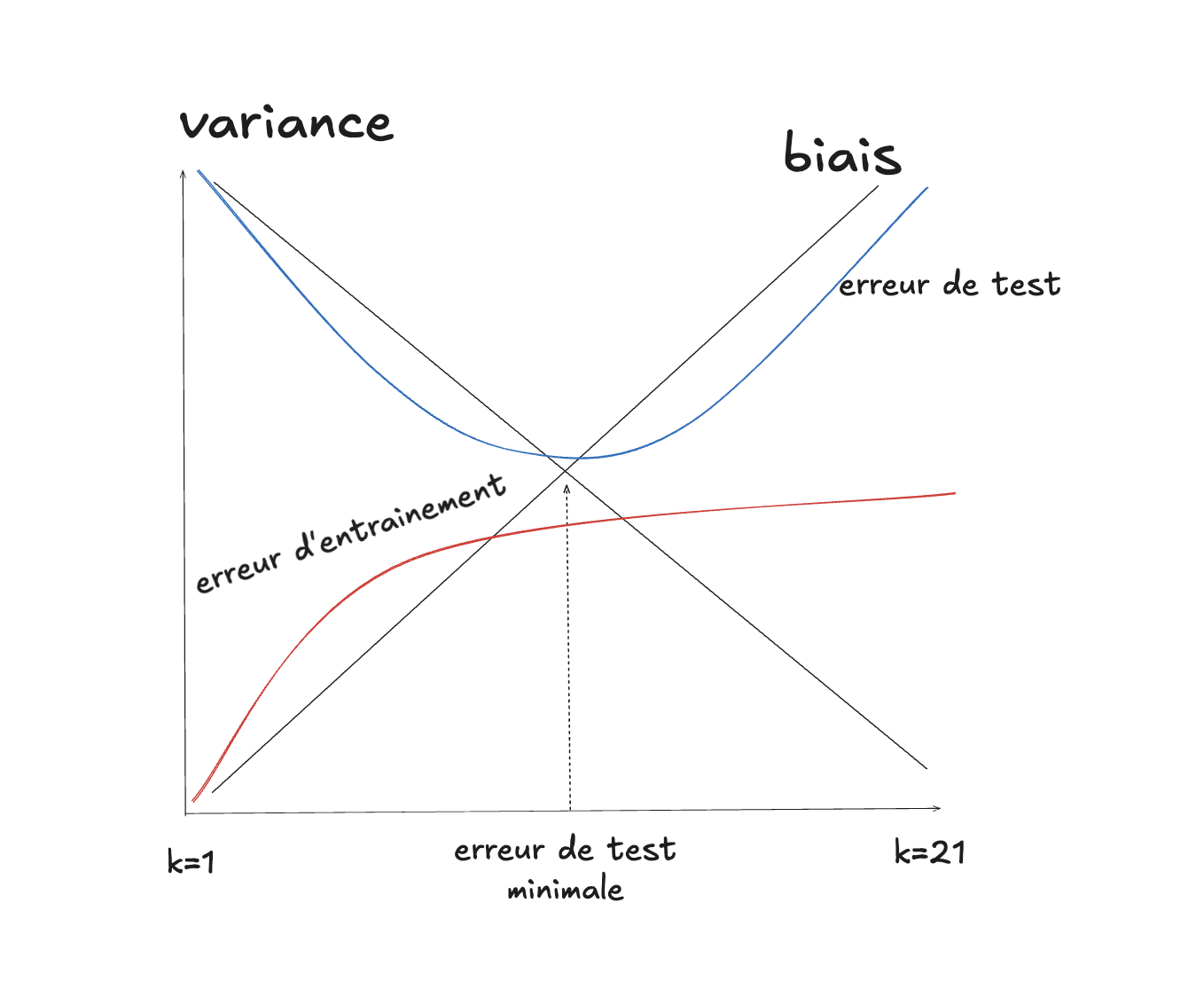
Nous verrons que ce principe est très général en apprentissage automatique, et qu’il permet de guider la recherche du “meilleur” modèle, celui dont les capacités de généralisation sont les plus grandes, ce qui constitue un des buts fondamentaux de l’intelligence artificielle.
Des résultats récents en apprentissage profond ont toutefois apporté de grandes surprises, car il semble que ce principe, qui était considéré comme étant immuable et indiscutable depuis des décennies, peut être, dans certaines circonstances, remis en question !