Le concept de similarité#
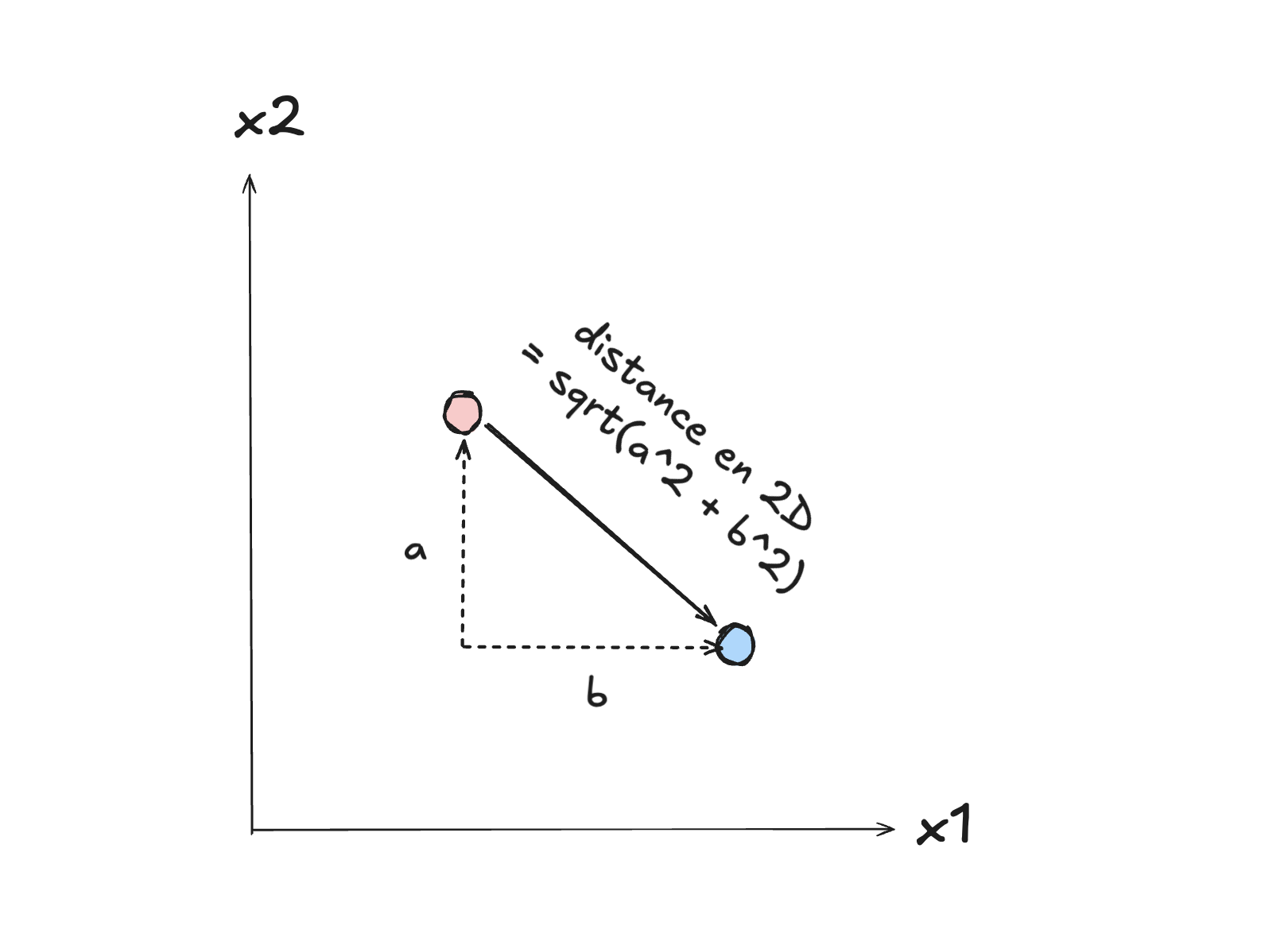
Nous avons vu avec l’algorithme des plus proches voisins qu’une notion essentielle est de pouvoir mesurer la distance entre deux objets, afin de déterminer à quel point ils sont similaires, qu’ils se ressemblent. Mais que veut-on dire exactement par cela? Pour de simples points en deux dimensions, nous avons une conception intuitive raisonnable : il s’agit de la distance euclidienne entre les deux points, qui se calcule à l’aide d’une formule mathématique simple.
Pour d’autres types d’objets (ou de données), comme des images, par exemple, bien que cela soit plus difficile à imaginer, il faut transposer son intuition géométrique dans un espace à plus haute dimension, par exemple un espace où chaque pixel d’une image correspond à une dimension :
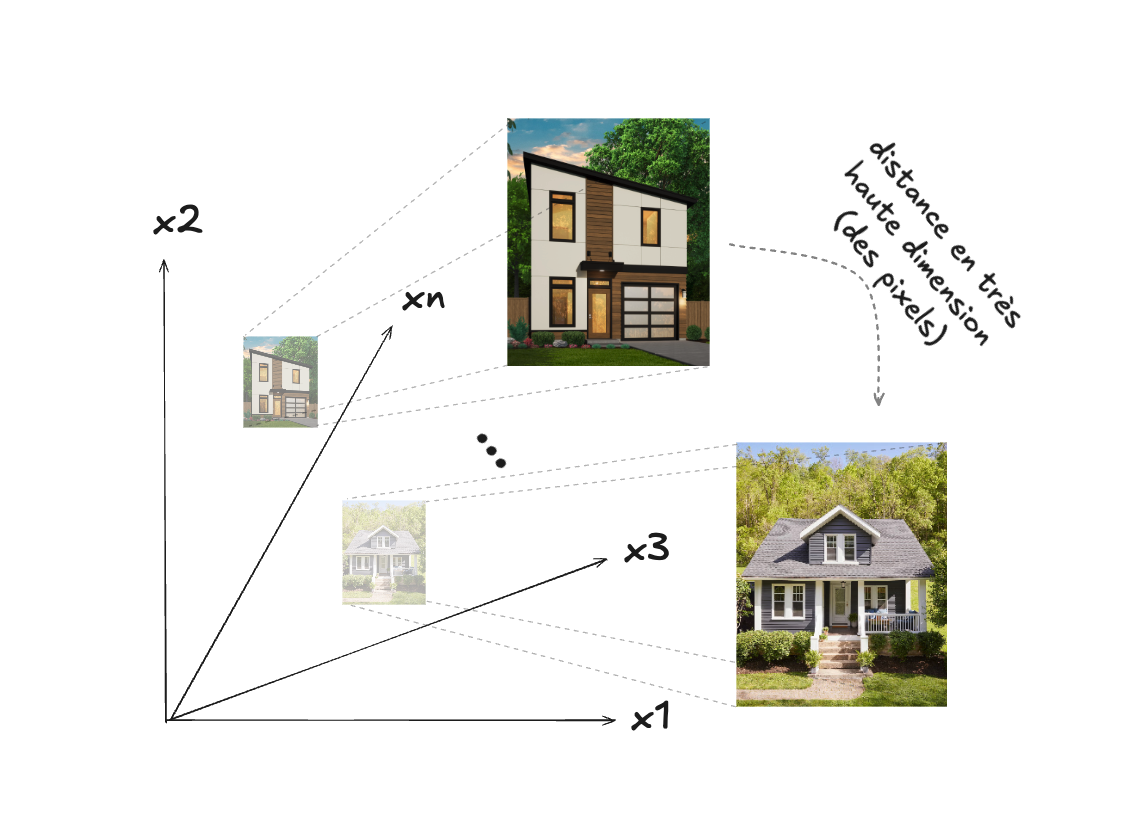
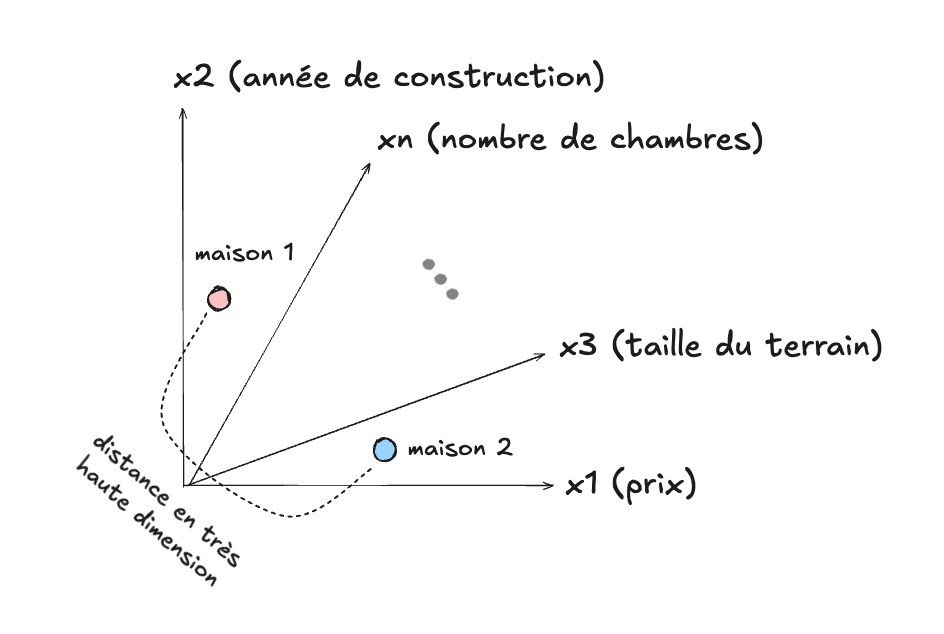
Dans ce sens particulier, une image correspond donc à un vecteur en très haute dimension, et exactement la même formule mathématique pour calculer la distance peut être utilisée. En fait pour la plupart des données de type numérique (comme par exemple les rangées d’un tableau Excel qui correspondent à des maisons en vente) il est possible d’utiliser la même représentation, comme nous l’avons vu déjà :
Distance entre les mots ou les concepts#
Mais supposons maintenant que nous voulions mesurer la similarité (distance) entre deux mots, ou deux concepts, que pourrions-nous faire?
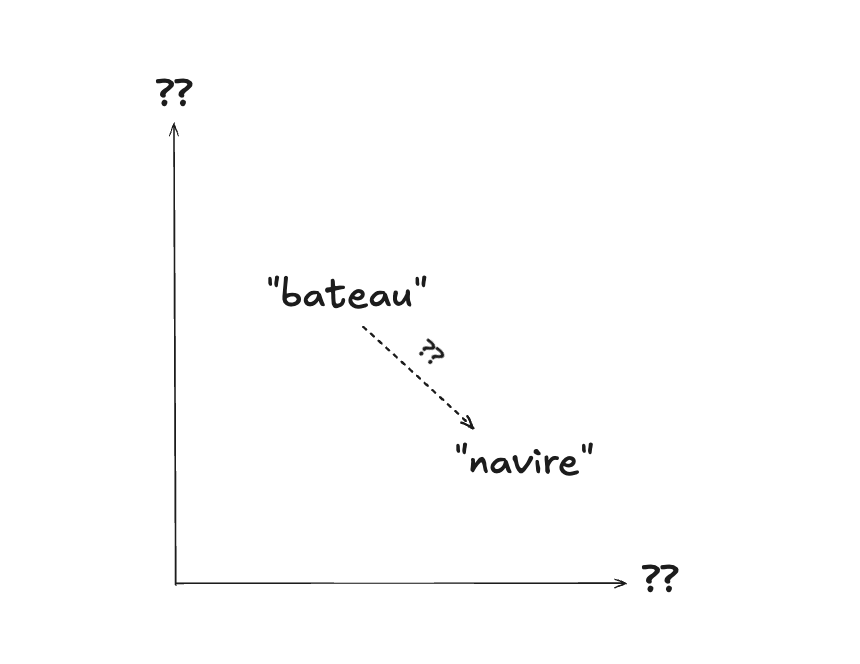
Une possibilité serait de considérer un espace composé par les 26 lettres de l’alphabet, où la présence d’une lettre dans un mot serait représentée par la valeur 1 dans la dimension correspondante, ou 0 sinon.
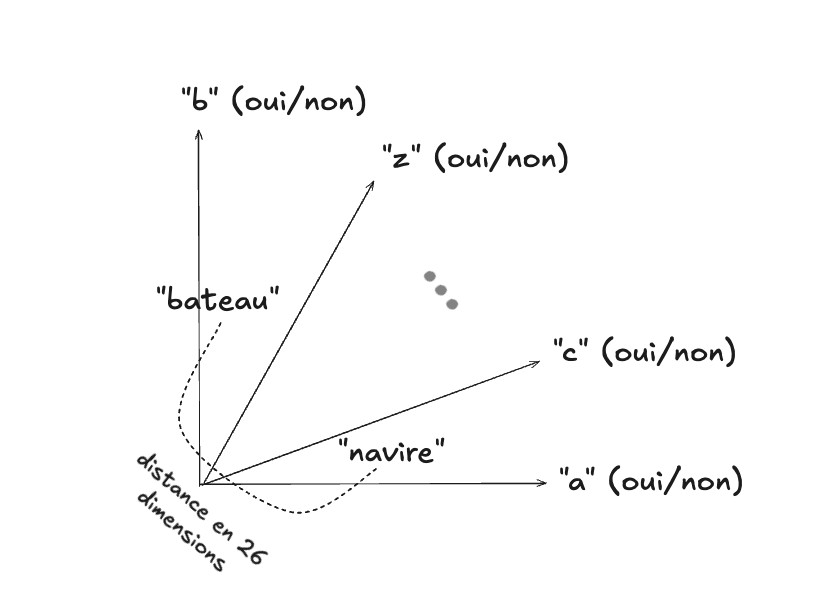
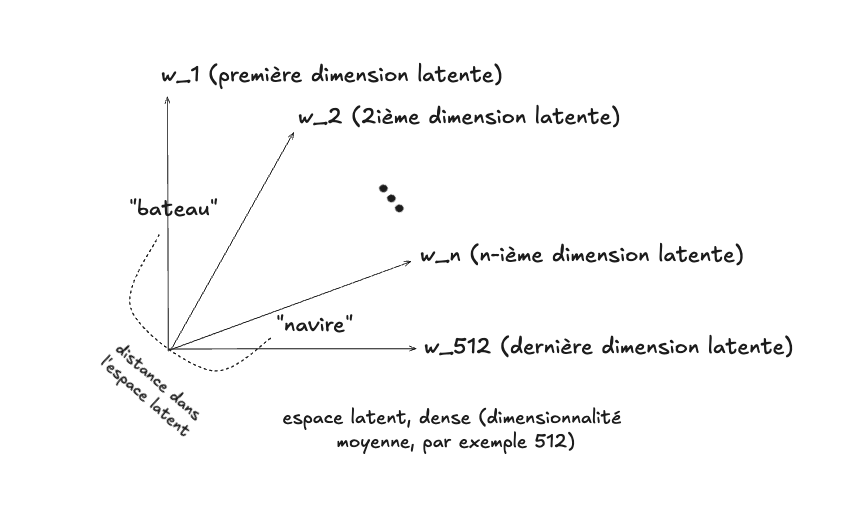
Si on y pense un peu, on se rend compte tout de suite d’un problème : les mots “navire” et “bateau” seront assez distants dans cet espace (alors qu’on voudrait qu’ils soient proches), tandis que les mots “amande” et “amende”, qu’on désirerait éloignés, seront très proches.
Distance de Levenshtein#
Une autre possibilité, très utilisée en pratique, est la distance de Levenshtein, (aussi appelée distance d’édition), qui permet de quantifier la différence entre deux chaines de caractères, en terme du nombre d’opérations à effectuer, pour transformer une chaîne en une autre. Utilisez l’application interactive ci-dessous pour mesurer la distance de Levenshtein entre les mots “navire” et “bateau” :
Bien que cette notion particulière de distance soit très utile pour faire des applications qui permettent par exemple de corriger des erreurs d’orthographe (ou de faire en sorte que les requêtes Google soient plus flexibles), elle est moins utile pour l’intelligence artificielle. Comment ChatGPT peut faire en sorte, par exemple, de considérer que les mots “navire” et “bateau” sont sémantiquement proches (et possiblement interchangeables), si les notions de distance que nous avons considérées jusqu’à maintenant ne permettent pas d’en offrir une mesure concrète?
Modélisation du contexte des mots#
Une manière de résoudre ce problème est de tenter de modéliser le sens des mots (ce qu’ils veulent dire) en considérant le contexte lexical qui a tendance à accompagner certains mots. Autrement dit, quels mots ont tendance à se retrouver dans le voisinage d’un mot particulier. On peut ainsi construire un espace vectoriel où chaque dimension correspond à un mot du vocabulaire. Un mot particulier, comme “chat”, par exemple, aura des valeurs qui correspondront aux mots qu’on a tendance à retrouver dans son contexte, comme par exemple : “ronronner”, “souris”, “miauler”, etc. On peut considérer que le sens du mot “chat” est déterminé par le champ lexical des mots qui ont tendance à l’accompagner.
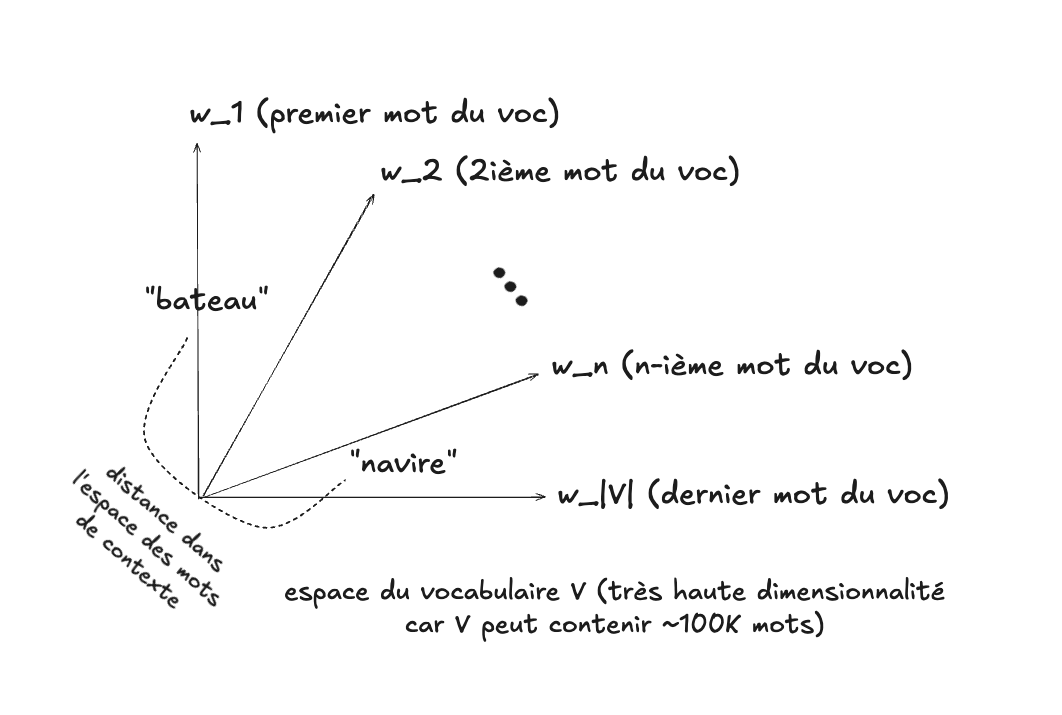
Cette approche fonctionne et est utilisée en pratique, mais elle présente tout de même des problèmes pour les algorithmes d’apprentissage automatique. Premièrement l’espace comporte un très grand nombre de dimensions (si on considère un vocabulaire de 100,000 mots, par exemple), dont la plupart seront de valeur zéro (car la plupart des mots ne se retrouvent pas dans le contexte immédiat d’un mot particulier). Les algorithmes d’apprentissage ont de la difficulté à opérer dans un tel type d’espace (beaucoup de dimensions, dont la plupart à zéro, donc de densité très faible). On parle parfois du fléau de la dimension (curse of dimensionality) décrire ce problème.
Les plongements lexicaux (word embeddings)#
Une autre solution est de représenter les mots dans un espace de dimension plus restreinte (par exemple 512 dimensions), dont la densité sera beaucoup plus grande (toutes les dimensions seront non-zéro, donc “utilisées”). La contrepartie avec un tel espace, ce que l’on perd, est la signification claire des dimensions. Si la dimension 127 du précédent modèle correspondait au mot “chat”, par exemple, ici, dans cet espace, elle ne correspond à aucun mot en particulier. On parle d’un espace latent. L’avantage d’une tel espace est qu’il constitue un substrat malléable, à partir duquel un algorithme d’apprentissage peut façonner sa propre représentation des mots et de leur sens, de manière interne. La position des mots dans cet espace, ainsi que la signification de ses dimensions, n’est pas déterminée d’avance, avant le début de l’entraînement. C’est plutôt le processus d’entraînement qui constitue leur définition, par un processus d’optimisation (la qualité de la représente augmente, à mesure que l’entraînement progresse). L’algorithme apprend le sens des mots, et s’en construit une représentation interne, qui lui est propre. Ce mécanisme de représentation particulier, qu’on nomme les plongements lexicaux (word embeddings) est ce qui explique, en grande partie, les extraordinaires capacités linguistiques de ChatGPT, le fait qu’il manipule si aisément le sens des mots.