Apprentissage automatique adverse#
Il existe un sous-domaine fascinant et troublant de l’apprentissage automatique, qui consiste à comprendre et étudier une de ses faiblesses étonnantes, les attaques adverses.
Voici tout d’abord un exemple fameux, provenant d’un article séminal de 2014 :

Dans certains cas pathologiques, il est donc possible pour un modèle de faire une erreur qui apparaît difficilement concevable pour un humain, à savoir classifier deux images pratiquement identiques, de manière complètement différente. Voyons comment ceci est possible.
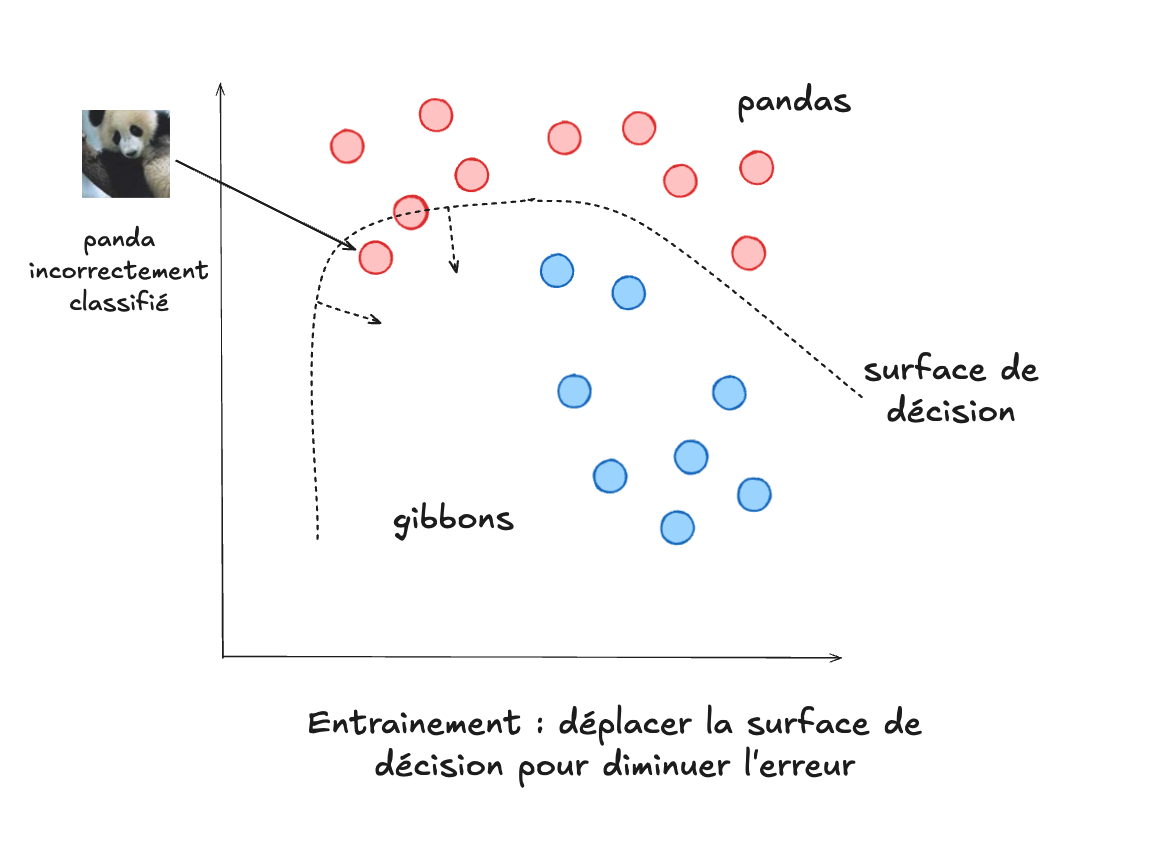
Nous avons déjà expliqué au deuxième module que le calcul effectué par un
algorithme de classification consiste d’abord à trouver la direction dans
laquelle les paramètres pourraient évoluer pour faire diminuer l’erreur (de
classification) de la manière la plus significative (la direction du gradient).
Une fois cette direction calculée, on modifie les paramètres du modèle (ses
poids) afin de les orienter dans cette direction. Ce faisant, on améliore la
performance du modèle, qui devient plus efficace pour déterminer si une image
est celle d’un panda ou d’un gibbon dans notre exemple. Même si la
correction se fait sur une erreur particulière, après une série de corrections
diverses (provenant de plusieurs images différentes), notre modèle devrait
pouvoir, idéalement, généraliser à la classification de nouvelles images.
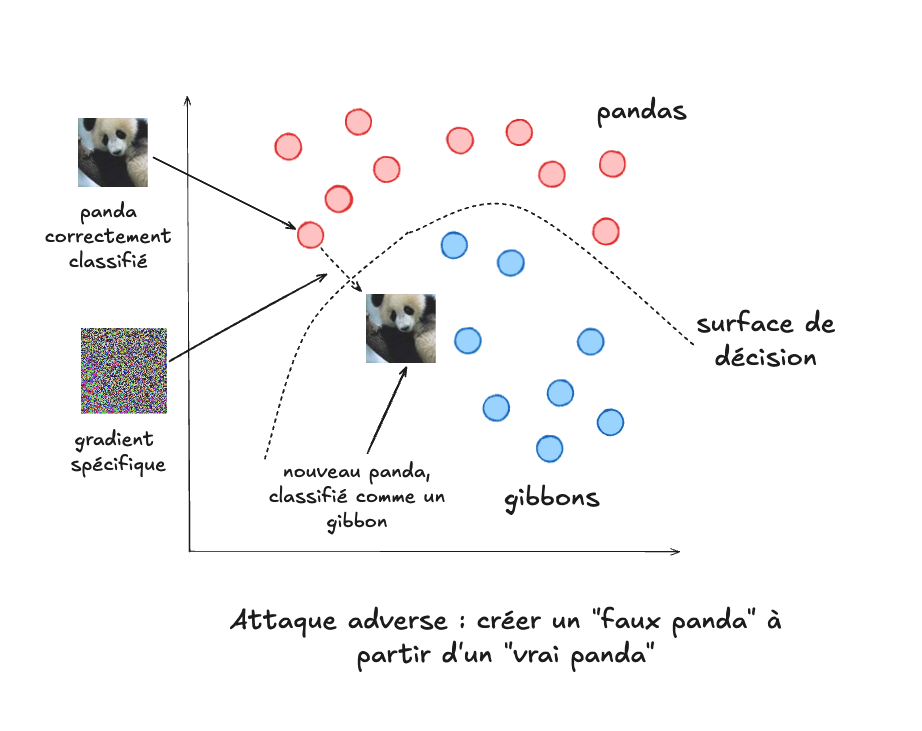
Imaginons maintenant que nous avons un modèle déjà entraîné. Pour produire une image adverse, par exemple celle d’un panda qui sera classifiée en tant que gibbon, on peut calculer le gradient dans la direction contraire de celle utilisée à l’entraînement, soit la direction où l’erreur augmenterait. Mais étant donné que le modèle est déjà entraîné, il n’est pas question de modifier ses paramètres, qui sont désormais fixés. La seule chose qui reste possible est de changer les pixels de l’image de départ, afin de créer une nouvelle image. Cette nouvelle image est modifiée en fonction du gradient, de manière à ce qu’elle se “déplace” dans la direction où l’erreur de classification sera augmentée. Et, de façon cruciale, nous voulons obtenir une image dont la perturbation sera minimale (c.-à-d. que les pixels seront modifiés de la manière la plus discrète possible), afin qu’elle continue de ressembler à un panda (tout en étant incorrectement classifiée en tant que gibbon).
Il est même possible d’aller encore plus loin, et de créer une image adverse encore plus proche de l’originale (dont la différence est donc encore moins facilement discernable), qui diffère seulement par un pixel :

Le fait que ceci soit possible devrait vous rendre perplexe et aussi légèrement inquiet. Cette perplexité est avant tout de nature scientifique et philosophique : comment se fait-il qu’une intelligence, même artificielle, puisse être trompée aussi facilement, par une simple différence de quelques pixels ? Du point de vue du jugement humain, cela paraît déconcertant. Ceci semble presque carrément contredire la notion même d’intelligence : si l’algorithme a réellement compris ce qu’est, de manière générale, un panda, ne devrait-il pas se montrer plus robuste, et ne pas se laisser berner aussi aisément? Pourtant, si on y réfléchit, l’esprit humain est lui aussi facilement abusé par de simples illusions d’optique :

Et finalement, pourquoi devrait-on être inquiet ? Eh bien, parce qu’il est possible d’utiliser des attaques adverses de ce genre sur des applications réelles d’IA, pour créer des effets néfastes. Il est par exemple possible de modifier légèrement un panneau routier, afin de tromper l’IA qui pilote un véhicule :

Cette étrange faille de l’apprentissage automatique ne se limite pas à la classification d’images. Elle concerne tous les types d’IA, y compris les grands modèles de langage, comme nous le verrons dans le prochain module. Elle constitue une source d’étonnement scientifique et philosophique, car elle montre clairement à quel point une intelligence artificielle est différente de son analogue humaine.