Les architectures neuronales avancées#
Une fois que les principes de base des réseaux de neurones sont bien compris, et que les idées de l’apprentissage profond sont plus claires, les choses deviennent foisonnantes et très intéressantes avec ce sujet !
Un peu comme on l’a fait avec l’ajout de couches cachées supplémentaires pour un réseau de neurones, si on prend un moment pour considérer son architecture, il est relativement facile d’imaginer des variations “topologiques” (des manières pour ses éléments d’être connectés en un graphe).
L’essor de l’apprentissage profond est venu avec une explosion de créativité à ce niveau, comme le démontre le fameux Zoo des réseaux de neurones :
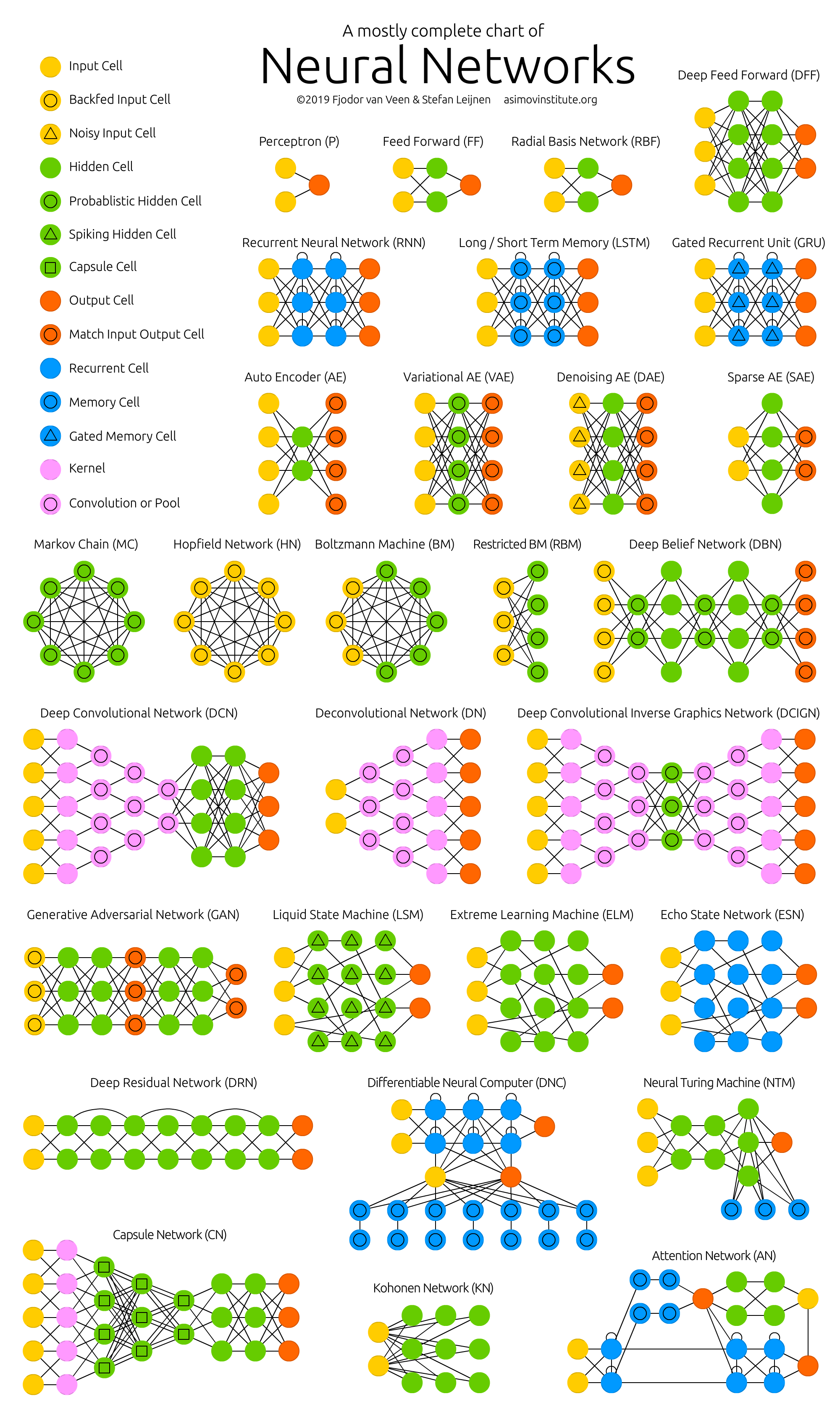
Nous allons faire un survol des architectures les plus importantes.
Les réseaux de neurones convolutifs (CNNs)#
Une limitation fondamentale des réseaux de neurones “traditionnels” (aussi appelés “feedforward”) est le fait que leurs neurones sont organisés en rangées unidimensionnelles. Si les données d’entrée du réseau sont une image, par exemple, la correspondance entre la structure 2D de l’image et la structure 1D de la couche d’entrée impose une difficulté supplémentaire au réseau, qui doit alors “découvrir”, par lui-même, le fait que certains pixels sont corrélés entre eux. Par exemple s’il y a une pelouse dans le coin inférieur gauche de mon image, les pixels qui se trouvent dans cette zone auront tendance à être verts, et le fait qu’un pixel particulier de cette zone soit vert “influence”, de ce fait, les pixels voisins.
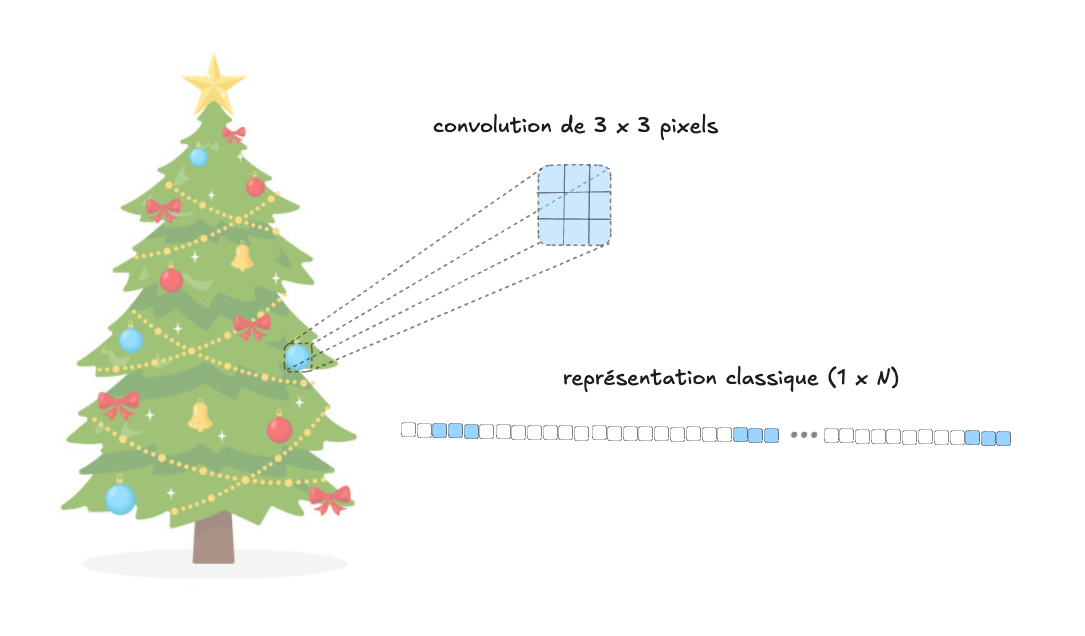
Les réseaux de neurones à convolution (CNN en anglais, ou ConvNet) sont particulièrement adéquats pour le traitement des images, parce qu’ils utilisent des convolutions, qui sont des petits “filtres” 2D (de quelques pixels de dimension) qui sont “glissés” sur l’image d’entrée, de manière à détecter efficacement certaines structures, à différentes échelles, dans une image (comme la boule de Noel bleue dans l’image par exemple, ou un oeil dans un visage). Un CNN est une collection de convolutions distinctes, dont la tâche est de détecter différents motifs dans les données, mais leurs paramètres exacts sont appris, plutôt que déterminés d’avance. Avant l’entraînement, les convolutions sont aléatoires, et si on entraîne avec un jeu de données qui contient des visages humains, elles deviendront progressivement spécialisées pour la détection de caractéristiques anatomiques. Si on entraînait plutôt avec un jeu de données de véhicules, la spécialisation prendrait une autre direction. Ceci veut donc dire que l’on ne décide pas d’avance de ce qu’on l’on voudra détecter, le réseau décidera par lui-même, et cela dépendra évidemment de la nature des images d’entraînement.
Les CNNs ont des architectures complexes, avec de nombreux détails :
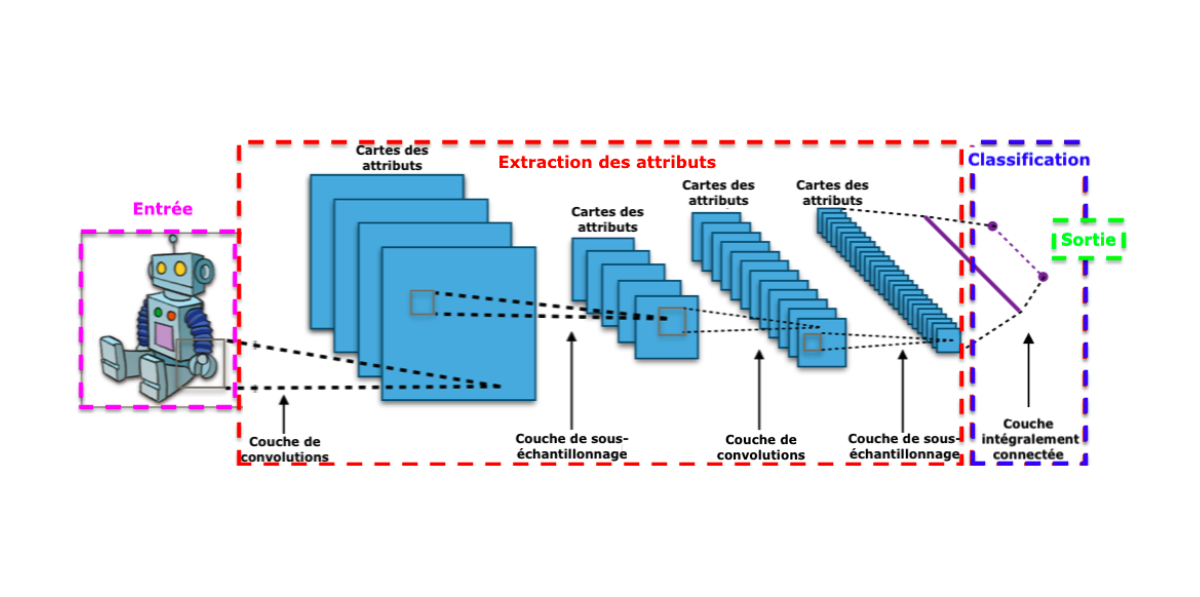
ImageNet#
Les CNNs ont joué un rôle particulièrement important dans l’avènement de l’apprentissage profond, en grande partie en raison d’un tournant, arrivé en 2012, lors du concours “Large Scale Visual Recognition Challenge” (ILSVRC), avec la base de données d’images ImageNet. Ce défi consistait à classer plus d’un million d’images en 1000 catégories différentes. Cette année-là, l’architecture AlexNet, un CNN profond entraîné sur GPU, a pulvérisé les performances de toutes les méthodes classiques (SVM, random forests, etc.), réduisant l’erreur de près de moitié. Ce succès a marqué le début de la révolution de l’apprentissage profond en vision par ordinateur : les CNN sont rapidement devenus la méthode dominante pour la reconnaissance d’images, puis pour de nombreuses autres tâches (détection d’objets, segmentation, analyse vidéo, etc.). Depuis, des architectures toujours plus sophistiquées (VGG, ResNet, EfficientNet, etc.) ont pris le relais, mais le point de bascule historique reste la victoire d’AlexNet sur ImageNet en 2012.
Avantages et applications#
Les CNNs sont plus efficaces que les RDN standards pour les images car ils partagent les poids (réduisant le nombre de paramètres) et exploitent l’invariance à la translation (un motif détecté, comme un oeil, n’importe où dans l’image est reconnu).
Applications courantes : reconnaissance d’objets (ex. : ResNet pour la classification d’images), détection faciale, ou même dans les voitures autonomes pour analyser les flux vidéo en temps réel.
Les réseaux de neurones récurrents (RNNs)#
Tous les types de données d’entrée pour les réseaux de neurones que nous avons vus jusqu’à présent étaient statiques, fixés dans le temps : une image, un point dans l’espace, les attributs d’une maison (son prix, ses dimensions, etc). Est-ce qu’il serait possible de prendre en considération des données séquentielles, qui s’articulent dans le temps, comme la musique, les mots (prononcés ou écrits), etc?
Il est tout à fait possible de présenter à un réseau de neurones une série
d’images séquentielles, comme celles d’un film par exemple. Mais le problème est
que chaque image sera traitée de manière indépendante. C’est comme si le réseau
repartait de zéro, à chaque exemple qu’il traite. Il faudrait introduire un
mécanisme pour modéliser un “état” dans lequel se trouve le réseau. Par exemple,
si on lui présente une suite de mots, et que les trois premiers sont bonjour,
comment et ça, il devrait être possible pour le réseau d’avoir un certain
“souvenir” de ceux-ci, quand il traite le prochain mot (probablement le mot
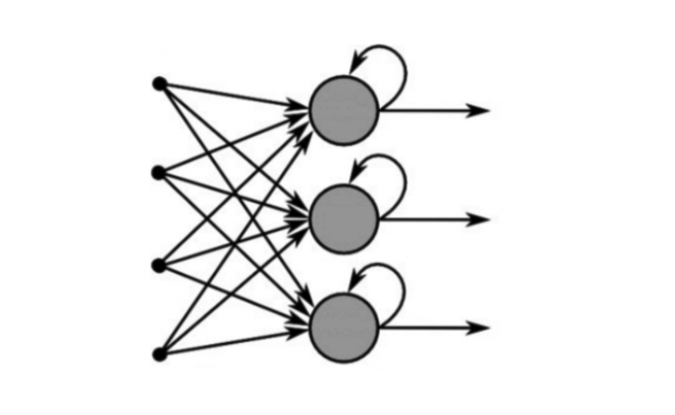
va). Les réseaux de neurones dits récurrents (RNNs en anglais) introduisent
dans leur architecture des boucles de rétroaction, permettant au réseau de
conserver une “mémoire” des états précédents.
Concrètement, et dans sa version la plus simple, ceci veut dire ajouter une couche de poids récurrents (ou réentrants) à la couche cachée. Si la couche cachée a $h$ neurones, ceci introduira donc une matrice de poids (paramètres) additionnels de $h \times h$ éléments.
Le problème du “gradient qui devient trop petit”, dont nous avons discuté dans une section précédente est particulièrement important avec les réseaux récurrents. Si on y pense un peu, ceci est à prévoir, car si on “déroule” un réseau récurrent, il est clair que ça correspond à une structure avec plusieurs couches successives, ce qui fait en sorte d’introduire de l’instabilité numérique au niveau du calcul de gradient (en gros, parce que les multiplications répétées de nombres très petits deviennent de plus en plus difficiles, pour un ordinateur digital). Une des méthodes pour remédier à ce problème est de rendre l’architecture encore plus complexe, comme c’est le cas par exemple avec un réseau LSTM (Long Short-Term Memory) :
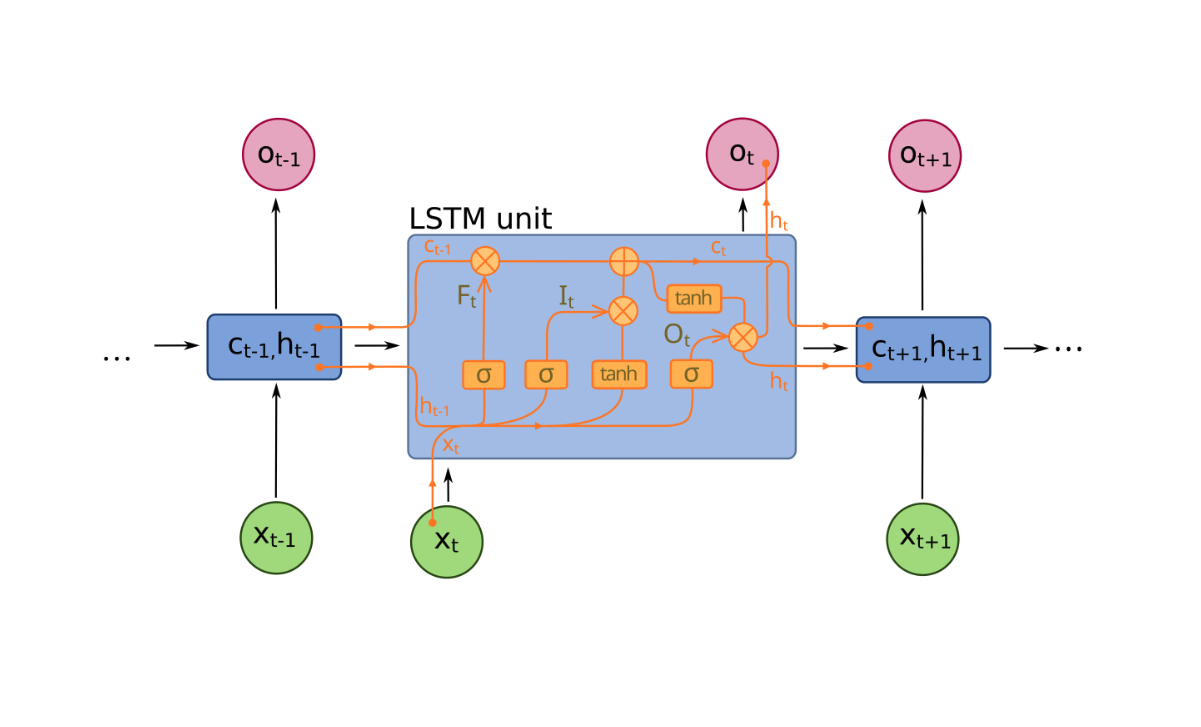
L’idée du LSTM est d’introduire des “portes” (sortes d’interrupteurs) qui régissent le flot de l’information, en faisant en sorte que la topologie (les connexions entre les éléments) devienne dynamique et changeante, au lieu d’être fixée d’avance. Si une porte est fermée (valeur 0) alors c’est comme si la connexion correspondante ne se faisait plus. L’état de ces portes n’est pas fixé d’avance cependant, il est plutôt “appris” par le réseau, c’est-à-dire qu’il est soumis lui aussi au régime de le rétropropagation, ce qui implique donc que ces portes doivent avoir leur propre jeu de paramètres qui leur sont propres.
Il est à noter qu’il est possible d’utiliser un réseau récurrent pour créer un modèle de langage (le mécanisme qui se trouve au coeur d’applications comme ChatGPT, par exemple), mais comme nous allons le voir plus loin, il existe maintenant un type de réseau de neurones encore plus puissant (les transformers) qui permettent de faire cela encore plus efficacement.
Applications : prévision de séries temporelles (ex. : bourse), traduction automatique (ex. : Seq2Seq), ou reconnaissance vocale (ex. : dans les assistants comme Siri).
Les autoencodeurs#
Un autoencodeur est une idée simple mais intrigante : supposons que nous connections ensemble deux réseaux de neurones, le deuxième inversé par rapport au premier, que pourrions nous en tirer?
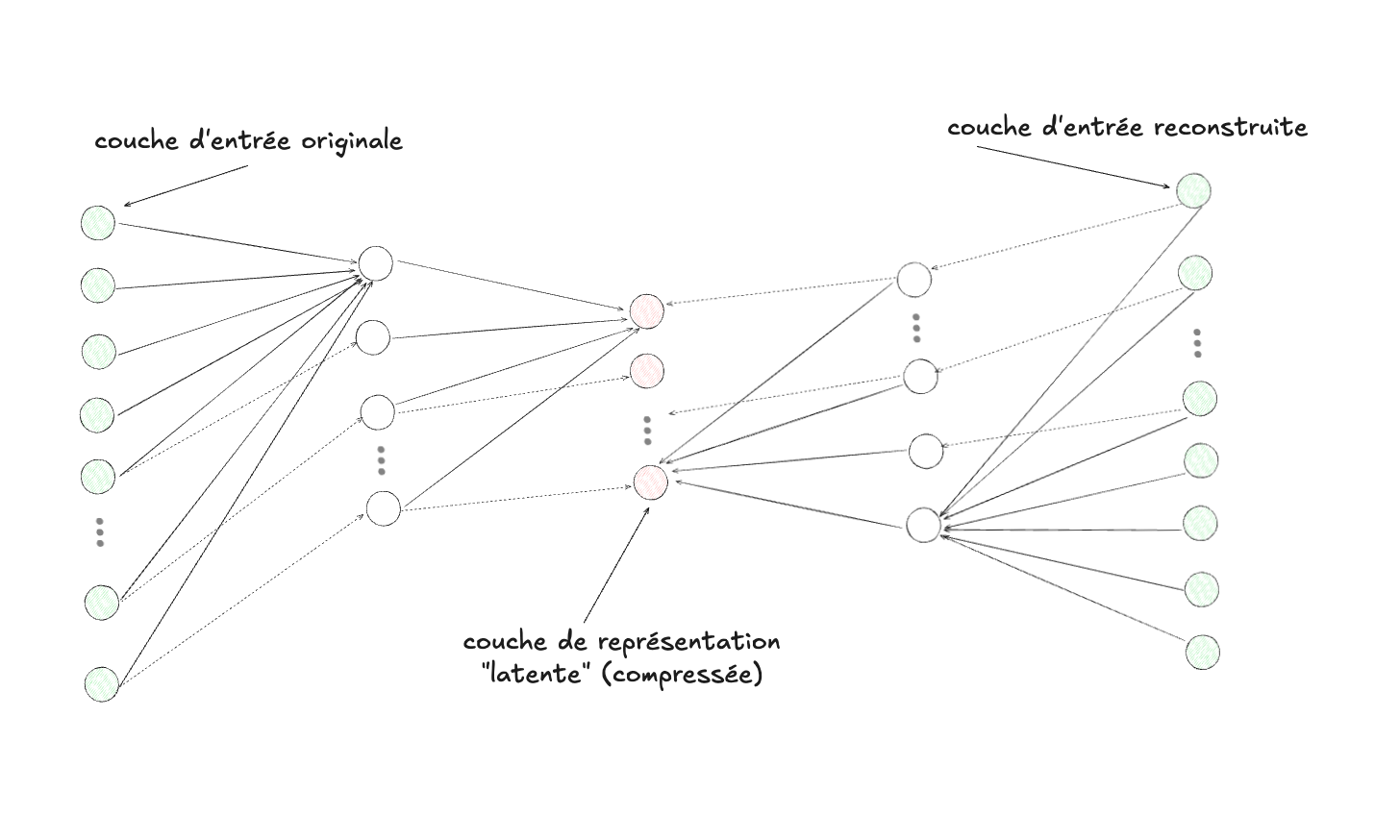
Il faut tout d’abord distinguer les deux parties de ce réseau de neurones particulier, soit l’encodeur, à gauche, et le décodeur, à droite :
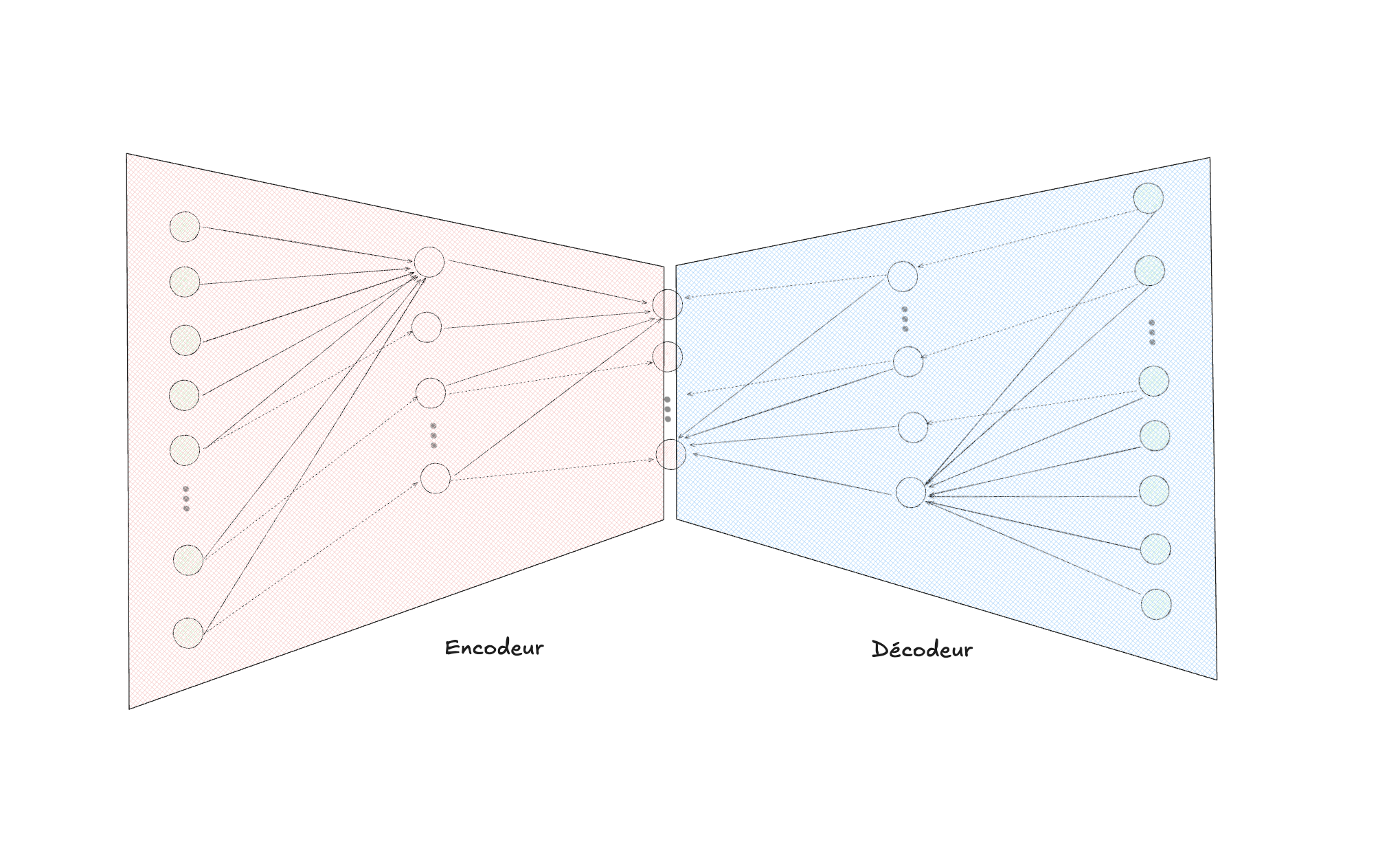
Un autoencodeur est un algorithme d’apprentissage dit auto-supervisé, car sa tâche est de tenter de reconstruire l’image d’entrée. Autrement dit, si on donne une image en entrée à un autoencodeur, et que sa sortie (c-à-d les neurones complètement à droite) la reproduit parfaitement, alors l’erreur est nulle (ce que l’on souhaite). Mais quel est donc l’intérêt de faire cela? L’intérêt réside dans la partie centrale du diagramme, soit la sortie de la couche d’activation de la couche cachée la plus petite au milieu de l’autoencodeur. Étant donné la structure du réseau et la fonction de reconstruction qu’il optimise, la couche centrale contiendra, une fois entraînée, une version correspondante de l’entrée (qui vit dans un espace à haute dimensionnalité, comme c’est le cas par exemple d’une image avec ses pixels), projetée dans un espace de plus faible dimensionnalité, dit latent.
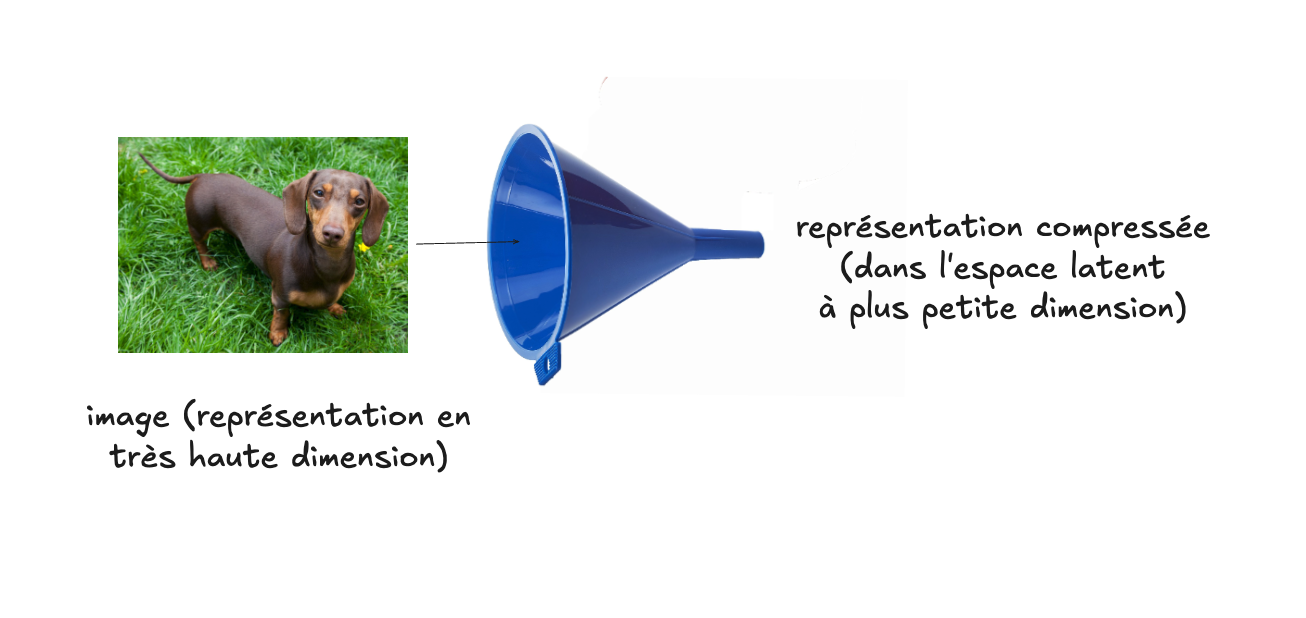
Cet espace latent est intéressant pour plusieurs raisons. Il constitue premièrement une représentation compressée des données d’entrée, et en considérant le diagramme et le fonctionnement de l’autoencodeur (la tâche de reconstruction qu’il accomplit), la raison devrait apparaître intuitivement assez claire : étant donné que le nombre de neurones de la couche latente est, par design, plus petit que celui des couches d’entrée et de sortie, c’est comme si on forçait les données dans un goulot d’étranglement (l’encodage), pour les rendre plus “compactes”. Mais étant donné que, de cette représentation réduite, on doit ensuite être capable de reconstruire l’image de sortie le mieux possible (soit la décoder), cela pousse la représentation compacte à préserver un maximum d’information (car si ce n’était pas le cas, la reconstruction ne serait tout simplement pas possible). On constate donc que, de par son design et son architecture, un autoencodeur constitue un mécanisme de compression (et de reconstruction) des données.
Quand on pense à la compression d’une image, on pourrait imaginer qu’il s’agit d’un mécanisme similaire à la compression JPEG par exemple, qui réduit la taille d’un fichier d’image, tout en la conservant visuellement identique (malgré qu’il y a une dégradation de la qualité qui peut être perceptible à des degrés variés).
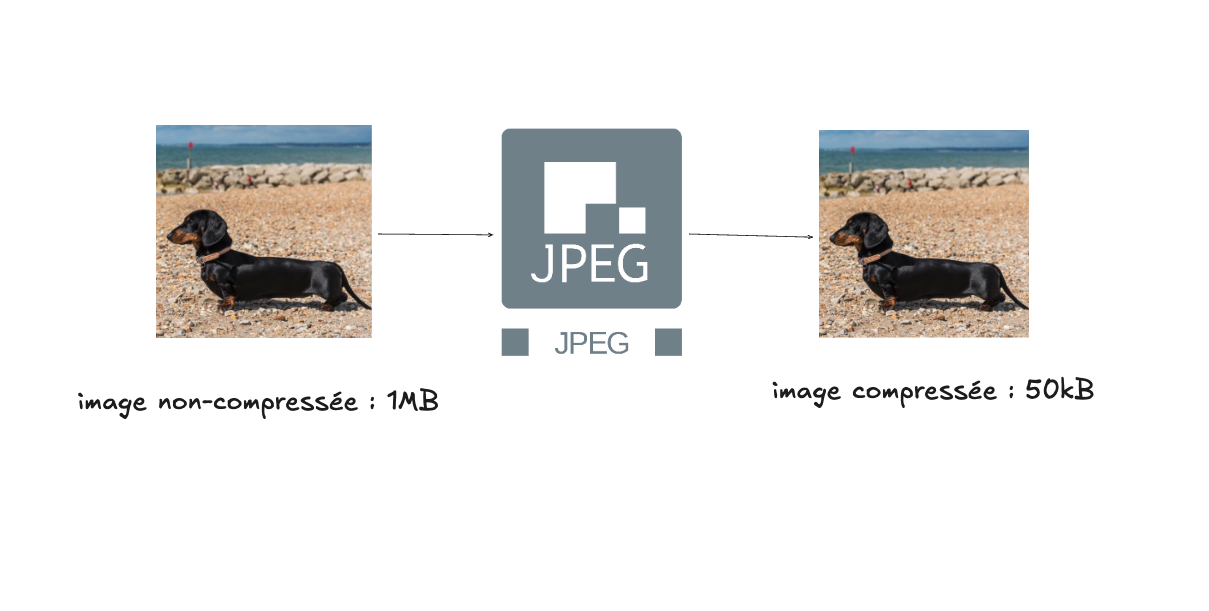
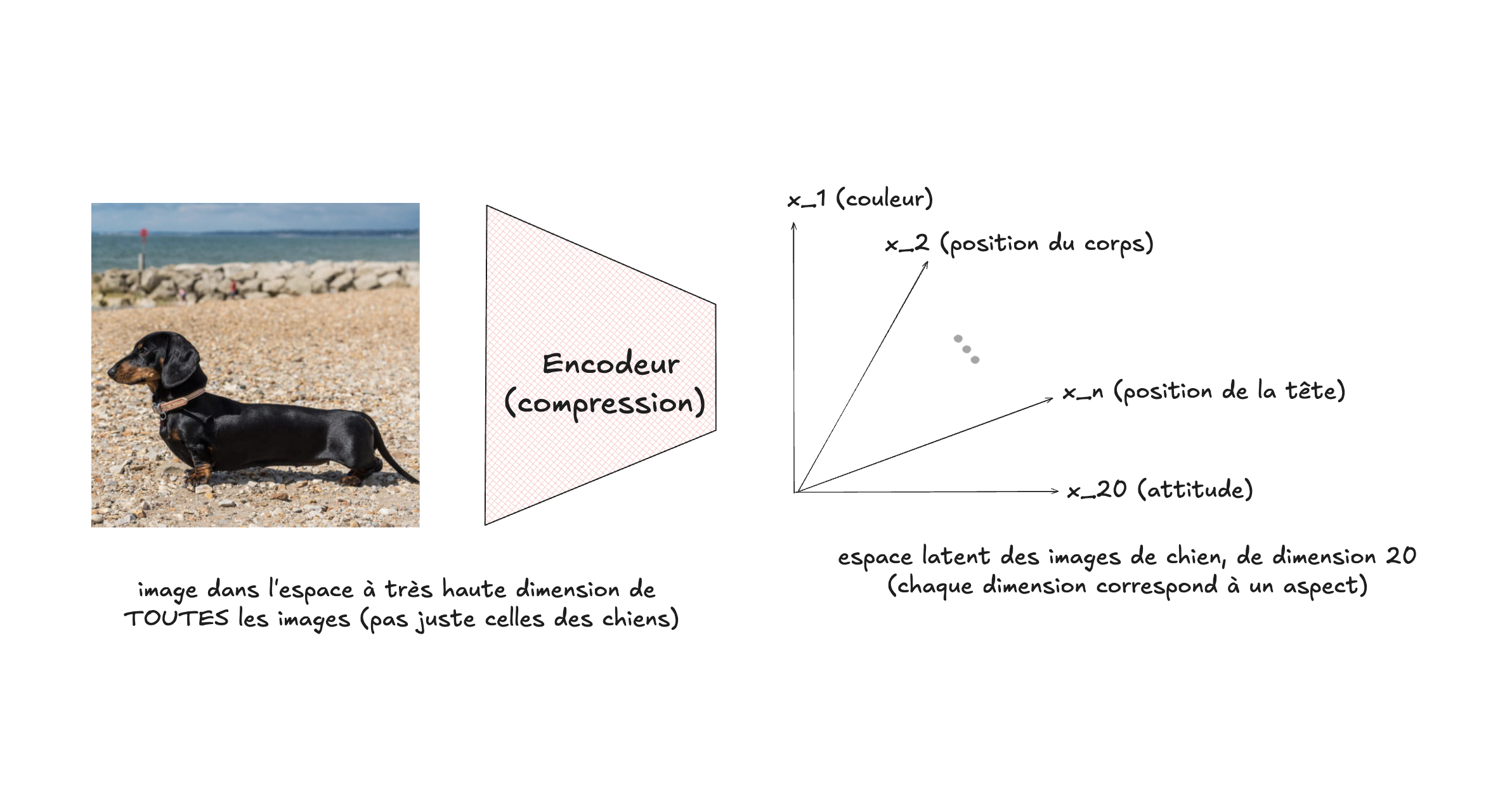
La compression effectuée par un autoencodeur est pourtant de nature très différente. Étant donné qu’il s’agit d’un algorithme d’apprentissage, qui traite de manière statistique une série d’exemples (par exemple des images de chien), le résultat de la compression est de nature sémantique : la représentation compressée obtenue sera interprétable. Par exemple, bien que ça ne soit pas garanti, il est très possible que les dimensions de l’espace réduit (latent) correspondent à des caractéristiques concrètes pouvant servir à l’interprétation d’une image de chien : une dimension correspondant à sa couleur, une autre à la position de sa tête, etc. Il est important de comprendre que l’espace original de l’image non-compressée, celui des pixels, ne comportent pas cette dimension sémantique. Il en est de même de la compression JPEG, qui effectue son travail en prenant en considération les données d’un angle plus bas niveau, celui des bits d’information. La compression JPEG ne cherche qu’à optimiser le ratio entre le poids de l’image et sa qualité, tandis qu’un autoencodeur cherche plutôt à optimiser la généralité de la représentation obtenue.
L’auteur américain de science-fiction Ted Chiang a écrit un texte intéressant et provoquant, intitulé ChatGPT is a blurry JPEG of the web (en anglais seulement) qui traite de cette dualité entre l’intelligence humaine et artificielle, du point de vue d’une analogie avec la compression logicielle.
Les espaces latents sont un sujet très riches et profonds, et ils ont de nombreux usages en apprentissage automatique. Par exemple, nous verrons que les transformers, qui sont un type de réseaux de neurones profonds qui servent de fondements aux grands modèles de langage (comme ChatGPT par exemple), en font usage. Nous avons déjà brièvement touché ce sujet dans la section sur les placements lexicaux (word embeddings).
Les réseaux de neurones pour les graphes (GNNs)#
Nous avons vu différents exemples de données que peuvent traiter les réseaux de neurones : des images, des séquences de mots ou de notes (un roman, ou une pièce musicale), des données tabulaires dans un tableur (Excel), etc. Mais les possibilités ne s’arrêtent pas là. Il est également possible de représenter des types de données plus abstraits, comme des graphes mathématiques, une structure de données très couramment utilisée en informatique. Un graphe est composé de deux types d’éléments :
- Des sommets
- Des arêtes qui relient les sommets (et qui peuvent avoir ou non une direction)
Notons tout d’abord qu’un réseau de neurones est, en soi, _déjà un graphe ! Les sommets sont les neurones, et les poids (paramètres) sont les arêtes. Mais le problème auquel on fait face est ici comment représenter un graphe (la structure de données) par un mécanisme (le réseau de neurones) qui est lui-même un graphe. Il s’agit donc, en quelque sorte, d’un graphe dans un graphe. Mais pourquoi voudrait-on faire cela? Parce que les graphes sont des objets mathématiques puissants et versatiles, qui ont de nombreux usages. Avec un graphe, il est par exemple possible de représenter un réseau de connaissances Facebook, et de suggérer de nouveaux liens. Il est également possible de modéliser les transports en commun d’une ville, ou des molécules pouvant servir à fabriquer de nouveaux médicaments. Un graphe encode une structure, avec des objets et leurs relations.
Un GNN (graph neural network) est donc un type de réseau de neurones capable de
représenter un graphe (dont la structure est connue d’avance), et de répondre à
certaines “questions” (ou requêtes) le concernant. Examinons tout d’abord
comment il est possible de représenter un graphe, à l’aide d’un réseau de
neurones (qui est lui-même une sorte de graphe, rappelons-le). Considérons tout
d’abord comment représenter les sommets. Supposons que nous ayons un graphe
simple avec trois sommets (A, B et C) et deux arêtes non-dirigées (A--B
et A--C). Chaque sommet est tout d’abord représenté par une liste de valeurs
de taille fixe. Il est important de comprendre la nature de ces valeurs numériques, qui sont au coeur du mécanisme de représentation. On peut
considérer que toutes ces définitions sont équivalentes :
- Une liste de $N$ nombres
- Un vecteur de dimension $N$
- Un plongement vectoriel (de nature très semblable aux plongements lexicaux que nous avons déjà rencontrés dans un chapitre précédent)
- En anglais, les termes “features” et “embeddings” (la traduction technique de “plongement”, un terme très rare en français)
Dans notre exemple, considérons des plongements de dimension $N=2$, choisis pour représenter chaque sommet. Au départ, ces valeurs sont arbitraires et aléatoires : elles ne veulent rien dire, en soi.
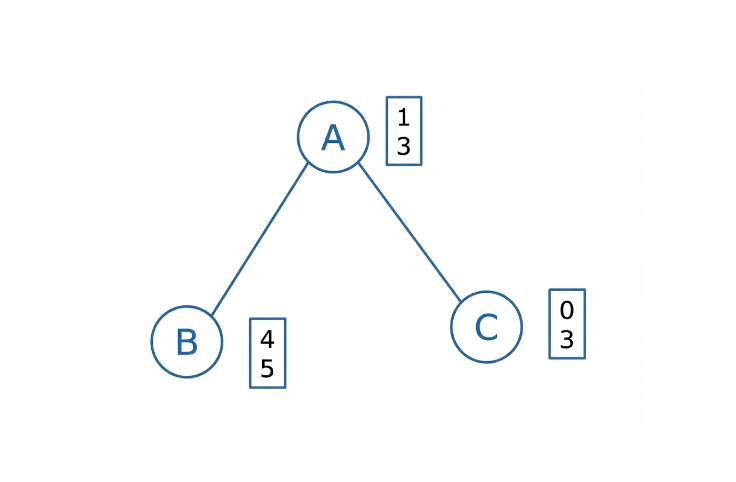
Nous avons donc là notre première couche de neurones, qui représente les sommets de notre graphe grâce aux plongements :
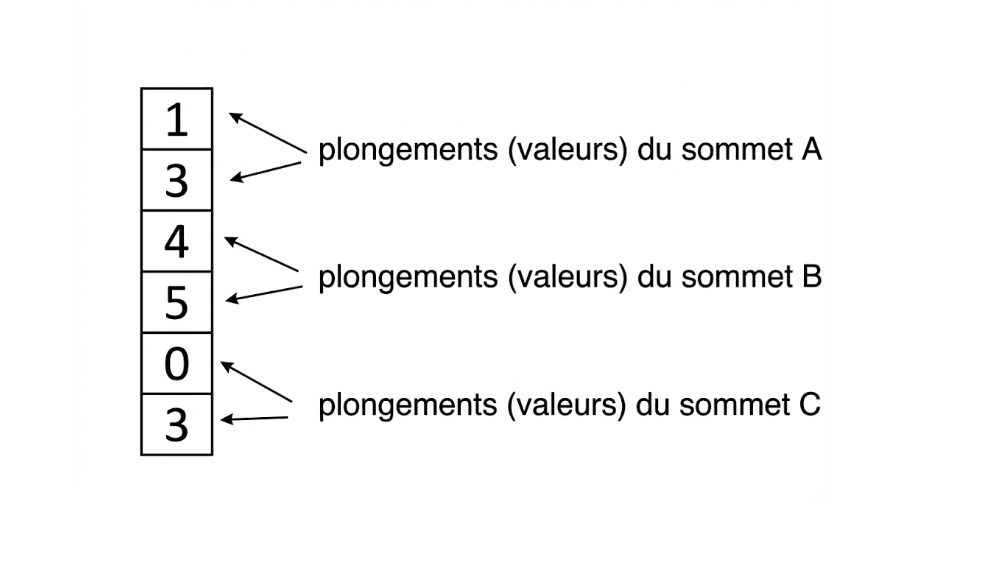
Comment est-il maintenant possible de représenter les arêtes? Intuitivement, il semble moins facile de représenter les arêtes que les sommets, car il s’agit d’objets dont la rôle est de relier deux sommets (contrairement aux sommets, qui sont des objets plus simples). Comment peut-on représenter une relation entre deux objets? Le mécanisme utilisé pour faire cela s’appelle le “passage de messages” (message passing), avec lequel chaque sommet envoie un “message” à ses voisins connectés par des arêtes. Ce “message” numérique permet au sommet de mettre à jour sa représentation, en prenant en considération celle de ses sommets voisins. La couche de départ est transformée par les messages, et ses valeurs sont donc changées.
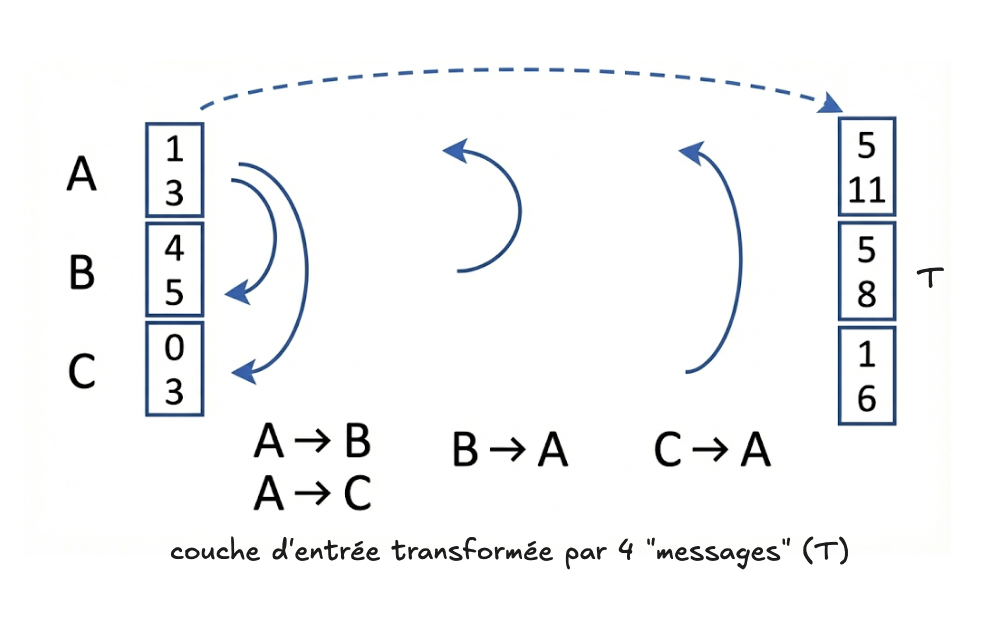
Un message est une opération mathématique simple entre les valeurs concernées : un
message entre A et C par exemple pourrait être simplement la somme (ou
encore, la moyenne) des valeurs (plongements) de A et des valeurs de C. Une fois cette
transformation effectuée (tous les messages passés et traités), on fait intervenir une couche de paramètres (une matrice $W$),
dont une des deux dimensions correspondra à la taille de notre couche d’entrée
transformée (6 dans notre exemple), une fois que la représentation des sommets a
été transformée par les “messages” envoyés à ses voisins (qui sont déterminés
par la structure du graphe, donc ses arêtes).
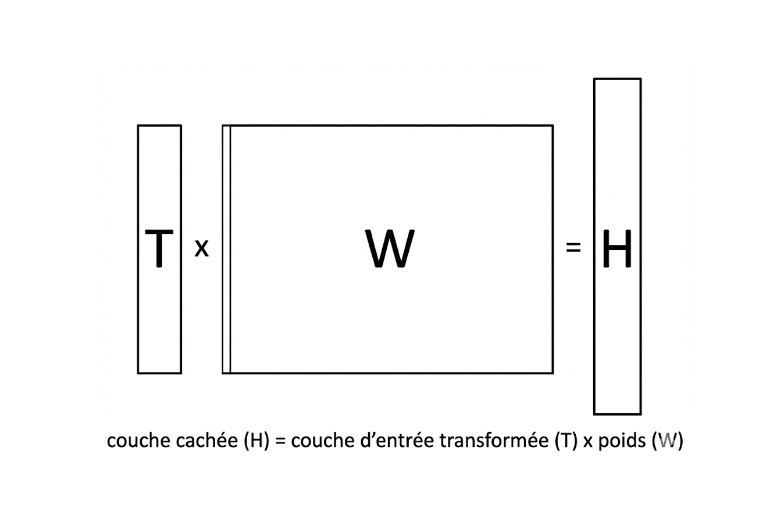
La reste de notre construction du GNN ressemble plus à un réseau de neurones traditionnel : la couche d’entrée transformée par les messages ($T$, de dimension 6) est ensuite multipliée par une matrice de paramètres ($W$, de dimension 6 x 8, qui seront “appris” par l’entraînement du modèle) pour résulter en une couche cachée $H$ (de dimension 8).
Étudions maintenant un vrai problème, qui peut être traité par un GNN. Le jeu de données Cora comprend :
- Une série de 2708 articles scientifiques (les sommets)
- Un vocabulaire de 1433 mots pour décrire chaque article
- 5429 liens (les arêtes) pour relier les articles entre eux
- 7 grandes catégories pour classifier les articles
La seule différence entre le modèle proposé dans un article séminal et celui que nous avons étudié ci-haut, se trouve au niveau de la représentation des sommets : dans l’article, les sommets sont représentés par des vecteurs de 1433 éléments qui ne sont pas des plongements, mais bien des vecteurs “creux” (ou parcimonieux, “sparse” en anglais) qui représentent de manière littérale la présence ou l’absence d’un mot. Nous avons tout d’abord rencontré cette idée dans la section précédente sur les sacs de mots. Un sac de mots, est “creux” dans le sens où, pour un article ou document donné, la plupart des mots du vocabulaire ne sont pas utilisés (donc leur valeur est zéro, et c’est seulement pour certains mots particuliers que la valeur sera autre que zéro). En contraste, un plongement est “dense” car les dimensions ne représentent pas des notions concrètes et discrètes. Chaque dimension d’un plongement correspond donc à une valeur non-zéro.
La tâche du réseau de neurones, dans ce cas particulier, est très classique : il s’agit de classifier chaque article en l’une de sept grandes classes (ou thèmes), connues d’avance. Le modèle particulier décrit dans l’article parvient à le faire avec une précision de 81%. Il est important de comprendre que ce résultat est bien supérieur à ce qui aurait été obtenu grâce à un modèle plus classique, qui utiliserait seulement les mots pour décrire les articles, au lieu de considérer les mots et les liens entre les articles. Le fait de considérer les liens, la structure entre les objets que l’on tente de modéliser, apporte une dimension beaucoup plus riche, qui permet de résoudre des problèmes de manière plus efficace.
Les machines de Turing neuronales (NTMs)#
La dernière architecture avancée que nous allons explorer dans ce module est celle des machines de Turing neuronales (NTM, ou Neural Turing Machines en anglais). Nous avons vu, avec les RNNs et les GNNs qu’il était possible pour un réseau de neurones de traiter des structures de données plus abstraites, comme des séquences ou mêmes des graphes. Il est même possible de traiter des structures encore plus générales. Une machine de Turing est une idée fondamentale en informatique et en mathématiques : la nature fondamentale d’un algorithme, c’est-à-dire quelque chose que l’on peut calculer, est d’être une sorte de mécanisme très simple, une “machine”. Cette machine est en fait un modèle théorique, et n’est donc pas une machine dans un sens conventionnel et concret. Une bonne manière de se représenter l’essence de cette machine théorique particulière est d’imaginer ses composantes fondamentales :
- Un ruban : une longue feuille quadrillée, infinie dans les deux directions. Chaque case contient soit un symbole (par exemple 0 ou 1), soit rien.
- Une tête de lecture : un petit curseur qui regarde une case du ruban, et qui peut lire, effacer, écrire un symbole.
- Une table de règles : une feuille avec des consignes du type : “Si tu vois un 0 et que tu es dans l’état A : écris un 1, déplace-toi la tête à droite, passe en état B.”
Ce modèle en apparence simple est extrêmement important et profond en informatique, car il permet de comprendre ce qu’est la nature fondamentale d’un ordinateur, ce qu’il peut et ne peut faire dans un sens logique profond. Par exemple, on peut concevoir un ordinateur pour calculer l’âge probable de la Terre, car il est possible de construire une machine de Turing simple (un algorithme), qui accomplirait cette tâche. Par contre, il n’est pas possible d’écrire un programme $P$ qui permettrait de déterminer si un autre programme $P’$ s’arrêtera ou non (sur une entrée particulière), car il possible de démontrer mathématiquement que ceci est impossible. Il n’existe tout simplement pas de machine de Turing capable d’accomplir cette tâche, car si elle existait, cela constituerait une contradiction logique.
Un programme classique (en dehors donc du contexte de l’apprentissage automatique) peut toujours être vu comme une machine de Turing particulière. Par contre, pour les modèles d’apprentissage automatique que nous avons vus jusqu’à maintenant, la correspondance est moins évidente. Elle est pourtant possible, comme l’existence des NTMs le démontre.
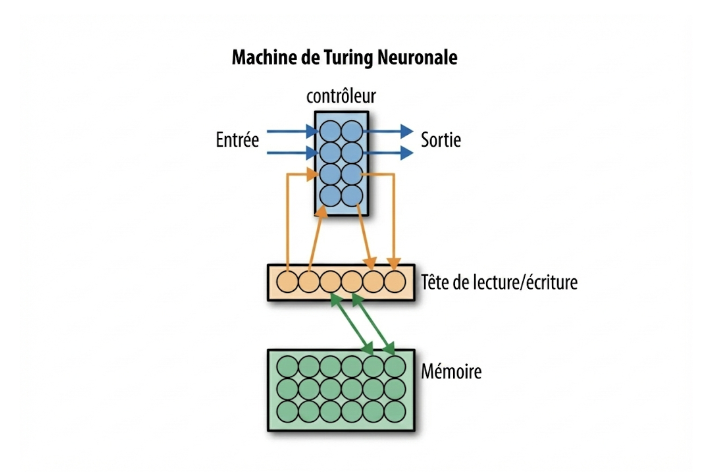
Il est possible de créer un réseau de neurones capable d’utiliser différentes structures de contrôle afin de reproduire un mécanisme similaire à celui d’une machine de Turing, donc d’un algorithme classique (comme par exemple un algorithme de tri, ou de multiplication). En particulier, un réseau de neurones de base n’a pas de “mémoire” au sens computationnel usuel du terme, celui d’un programme classique (qui a accès à la mémoire de l’ordinateur, avec des variables, etc). Pourtant, avec un NTM, le réseau de neurones acquiert une version particulière d’une mémoire, qui fonctionne d’une manière similaire à celle d’un ordinateur : il peut y sauvegarder de l’information de manière temporaire, qu’il va pouvoir relire plus tard. Il s’agit là d’un croisement particulièrement impressionnant entre le modèle computationnel classique et l’apprentissage automatique. Il s’agit donc, quelque sorte, d’une version “molle” d’un algorithme classique (au sens où l’est un algorithme d’apprentissage, qui est moins “rigide” qu’un algorithme classique, de par sa nature statistique). Nous allons voir dans le prochain module que l’IA moderne tend globalement à aller dans la direction d’innovations de ce genre.