Les réseaux de neurones#
Une généralisation de la régression logistique#
Sans le réaliser, au module 2, nous avons déjà vu un réseau de neurones (RDN) simple, mais qui portait alors un autre nom : la régression logistique (RL).
Une manière visuelle de représenter la régression logistique est la suivante (sous la forme d’un graphe, avec des noeuds (ou sommets) et des arêtes) :
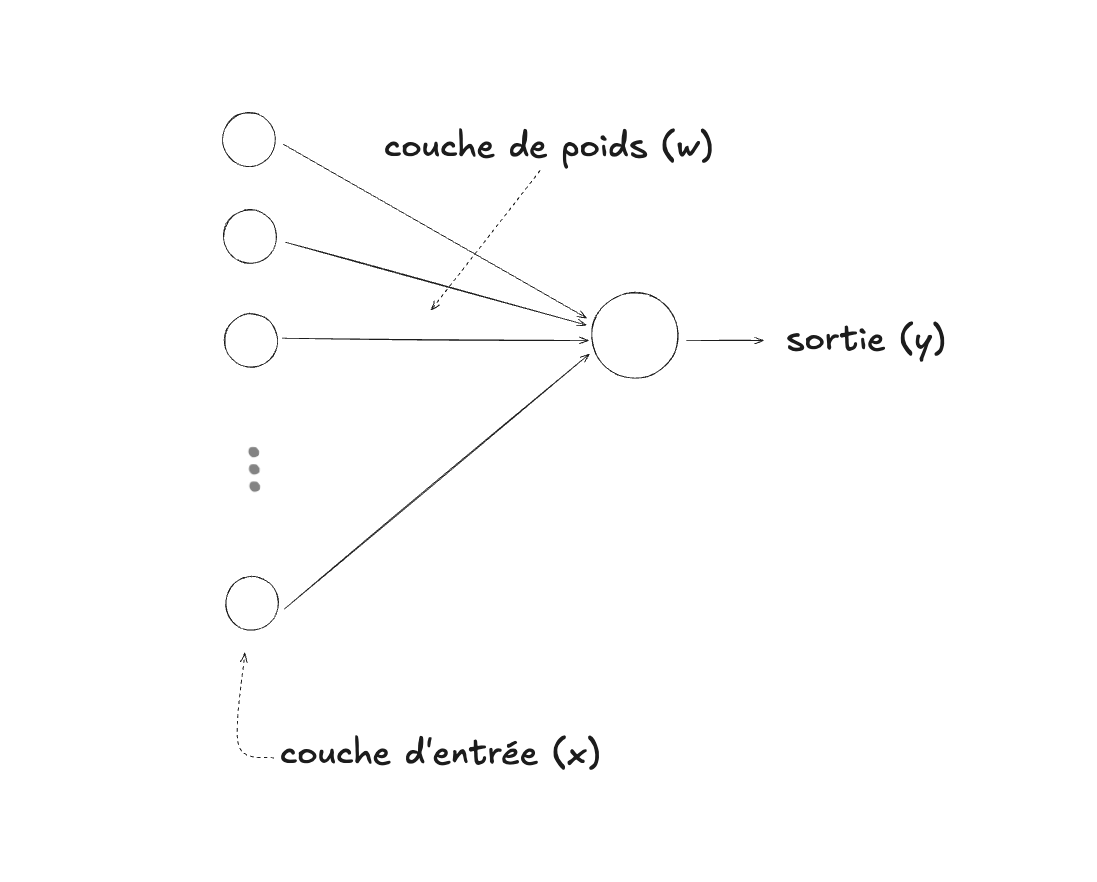
La couche d’entrée (la rangée de cercles à gauche) n’est pas vraiment une couche, elle représente simplement les données que l’on va fournir en entrée (input) à la RL, comme cette extension du même diagramme le démontre :
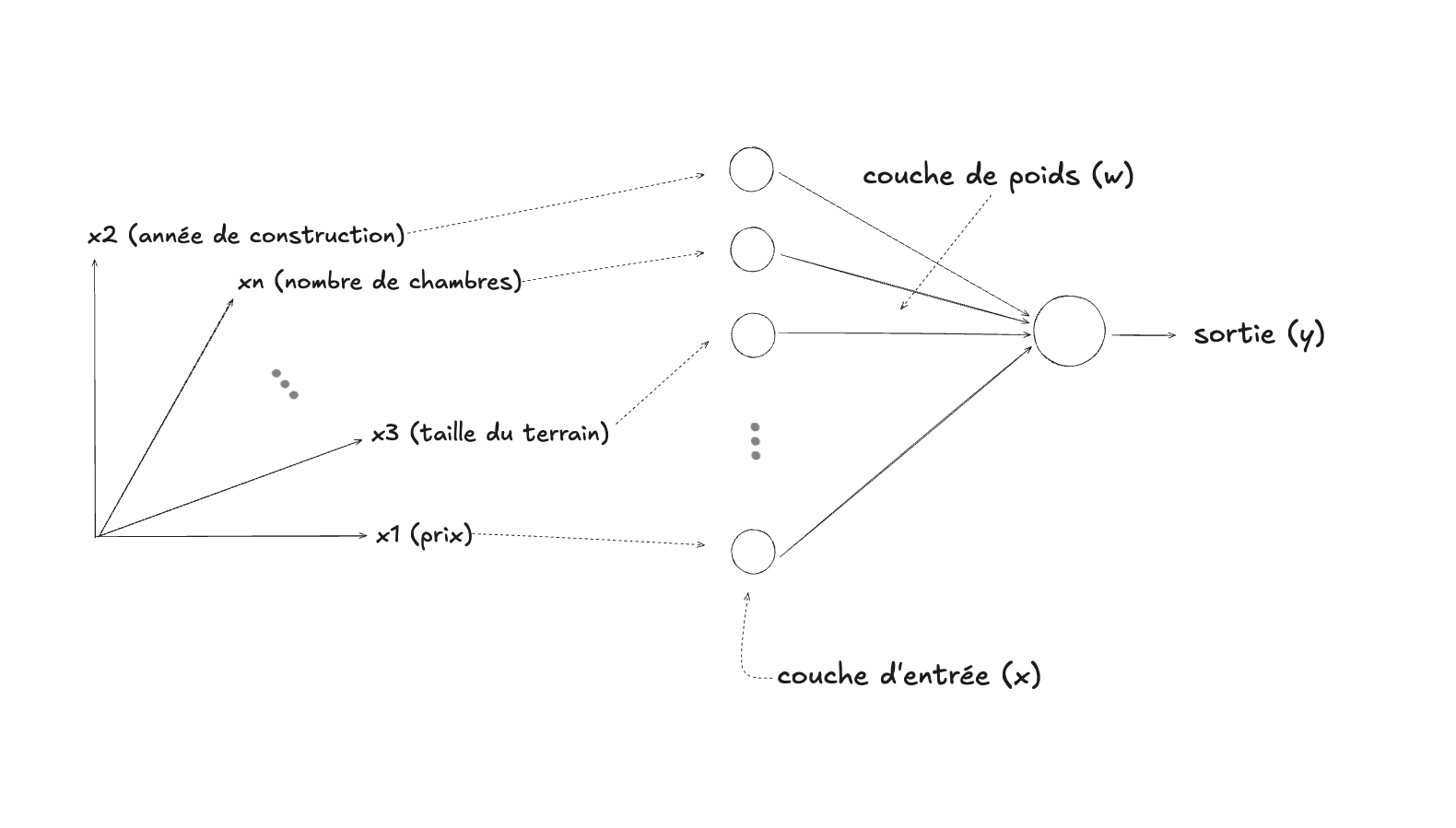
Comme nous l’avons déjà exploré au module 2, les données (la partie à gauche) sont la représentation vectorielle
(numérique et souvent multidimensionnelle) d’un aspect de la réalité, comme par
exemple ici, une maison à vendre, dont on aimerait déterminer (prédire), à
partir de ses caractéristiques (les variables $\mathbf{x}$ qui la décrivent), si
elle est à vendre ou non (soit la variable $y$, qui ne peut prendre que deux
valeurs possibles, 0 ou 1, que l’on peut interpréter comme non ou oui,
arbitrairement). Pour effectuer cette prédiction, la régression logistique
utilise les paramètres (la couche de poids $\mathbf{w}$, qui correspondent aux
flèches, ou aux arêtes du graphe), dont l’interaction avec les données va
produire la prédiction souhaitée (la sortie $y$ donc). Pour obtenir de bonnes
prédictions, on doit procéder à l’entraînement de la RL, ce qui correspond à la
recherche des valeurs optimales pour ses paramètres (les poids), qui vont faire
en sorte de minimiser la fonction d’erreur.
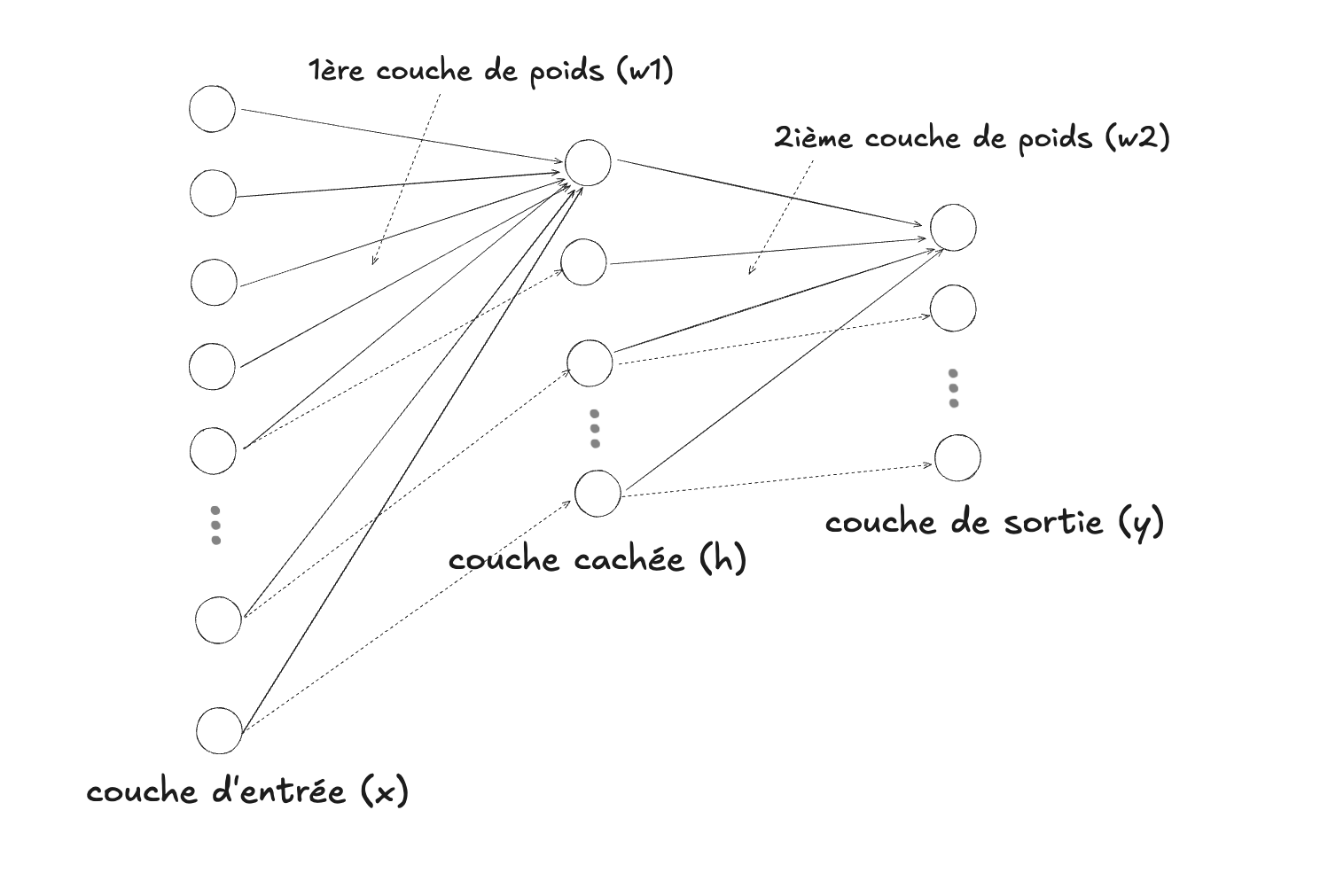
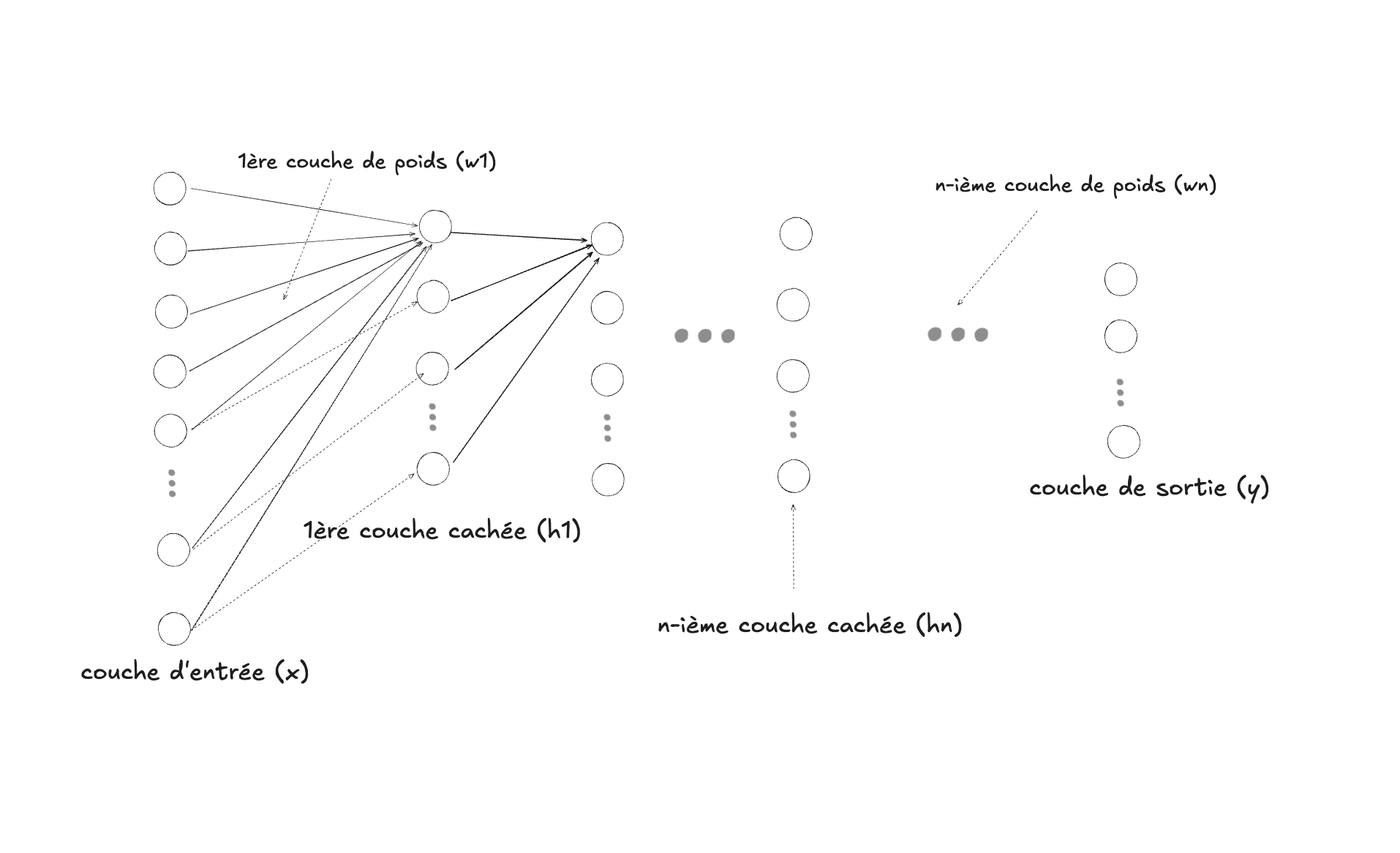
Voici maintenant un réseau de neurones. Il faut tout d’abord imaginer que le réseau de connexions (les flèches sur les diagramme) entre les neurones artificiels (les cercles sur les diagrammes) est total, c’est-à-dire que chaque neurone d’une couche est connecté à chaque neurones de la couche suivante. Le diagramme serait trop chargé avec toutes ces connexions, mais en principe elles sont là.
La première chose qu’on peut remarquer, c’est le changement de langage, qui nous transporte maintenant dans un domaine qui évoque plus l’intelligence : les neurones ! Il faut donc tout d’abord clarifier ce qu’on entend par neurone : il s’agit en fait d’un usage métaphorique, basé de manière très simpliste sur l’anatomie du cerveau. Voici un schéma qui aide à faire la correspondance entre les deux mondes (intelligence biologique ou artificielle) :
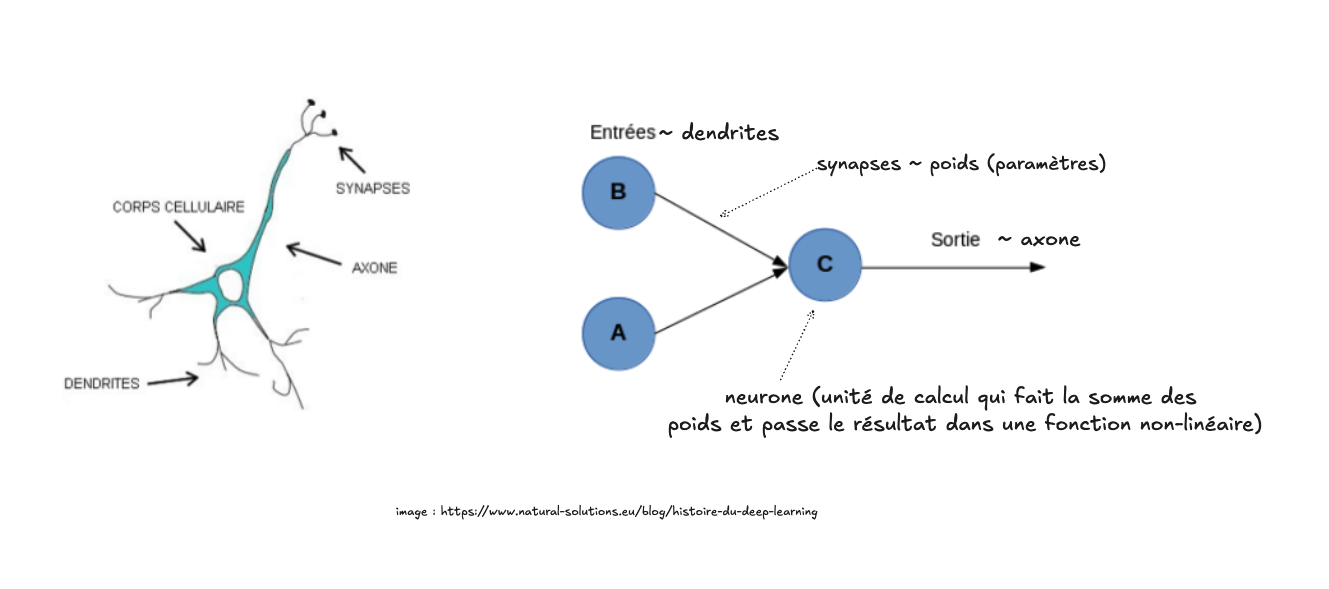
Le cerveau biologique est constitué d’un enchevêtrement de cellules nerveuses spécialisées (les neurones). Chaque neurone reçoit des signaux par ses dendrites, les intègre dans le corps cellulaire, puis transmet un signal électrique le long de son axone vers d’autres neurones via les synapses. De manière relativement analogue, notre notion de neurone artificiel (les cercles, ou noeuds dans les diagrammes) correspond donc à une “unité de calcul” qui “intègre” ses valeurs entrantes avec deux opérations mathématiques successives et simples :
- La somme (addition) des poids (synapses) qui lui sont connectés (les valeurs entrantes du neurone)
- Le passage de (1) dans une fonction d’activation (non-linéaire)
Dans nos deux diagrammes précédents (celui de la régression logistique et celui d’un réseau de neurones), la première couche (celle qui reçoit, ou connecte avec les données) n’est donc pas une couche de neurones dans le sens décrit, car elle ne contient pas ce mécanisme d’intégration. La RL a donc, par conséquent, un seul neurone au final, et un RDN plusieurs (dans la couche cachée et la couche de sortie). L’autre composante qui fait en sorte qu’il s’agit d’un réseau sont les synapses (pour le cerveau biologique) ou les poids (pour un réseau de neurones artificiels). Dans le cerveau, la transmission des signaux se fait selon un mécanisme très complexe, mais dans un RDN, les poids sont simplement des valeurs numériques, habituellement rassemblées dans une matrice : si une couche de $N$ neurones est reliée à une autre couche de $M$ neurones, il y aura donc une matrice de $N \times M$ poids pour établir la connexion.
Si cette description en mots vous apparaît un peu laborieuse, voici un exemple interactif qui pourrait vous aider à clarifier les idées. Changez les valeurs d’entrées, ainsi que celle des poids (paramètres) et convainquez-vous que vous avez une compréhension claire de ce mécanisme relativement simple :
La somme de la multiplication des valeurs du vecteur d’entrée ($\mathbf{x}$) et celles du vecteur de paramètres ($\mathbf{w}$) est représentée par la lettre grecque sigma majuscule ($\Sigma$), tandis que la lettre sigma minuscule ($\sigma$) représente la fonction d’activation sigmoïde, qui transforme une valeur arbitraire (n’importe quel nombre) en une valeur correspondante, entre 0 et 1.
Le réseau de neurones introduit donc, par rapport à la RL, une couche intermédiaire de neurones (la couche dite cachée, entre la couche d’entrée et celle de sortie), ainsi qu’une couche de poids supplémentaire, entre la couche cachée et celle de sortie. Une autre différence est qu’il y a un nombre variable de neurones de sortie, ce qui veut donc dire que le résultat ne sera pas nécessairement un seul nombre (qu’on interprétait dans le cas de la régression logistique toujours en tant que probabilité). On peut donc considérer qu’une régression logistique est un cas spécial d’un réseau de neurones, sans couche cachée, et avec un seul neurone de sortie.
Ce fonctionnement en cascade rappelle la structure et le fonctionnement du cerveau humain : des «entrées » qui véhiculent l’information, des « noeuds » qui effectuent un calcul ou une transformation, et des « sorties » transmises à d’autres unités. De la même manière que l’intelligence du cerveau émerge de la combinaison massive et parallèle de ses cellules, l’apprentissage automatique exploite l’interconnexion d’un grand nombre de neurones artificiels pour produire des comportements complexes à partir de règles simples. Ce paradigme computationnel particulier, pour implémenter des comportements intelligents, se nomme le connexionnisme. Le connexionnisme, quand il s’agit d’intelligence artificielle et d’ordinateurs, est fondamentalement différent de la programmation traditionnelle, symbolique.
L’entraînement avec la rétropropagation du gradient#
Nous avons déjà vu que la régression logistique est entraînée à l’aide de la technique de la descente de gradient. Le but est de changer graduellement les valeurs de sa couche de poids, de manière à minimiser une fonction d’erreur. La même technique est utilisée pour l’entraînement d’un RDN, mais elle doit évidemment composer avec la structure plus complexe du réseau, qui comporte plus d’éléments (au moins une couche de poids, et une couche de neurones supplémentaire). Étant donné que la descente de gradient utilise la notion de la dérivée partielle de la fonction d’erreur, il est possible d’utiliser la règle de la chaîne pour calculer le gradient à travers tous les éléments du réseau (les sommes de poids, les fonctions d’activation, etc). Cet algorithme très fameux et puissant se nomme la rétropropagation du gradient (backpropagation en anglais), et il se trouve au coeur de l’intelligence artificielle moderne. On le retrouve partout, de la fonction de recherche thématique dans Google Photos à ChatGPT.
Pour bien comprendre l’entraînement d’un RDN, il faut considérer qu’il y a deux phases dans son fonctionnement.
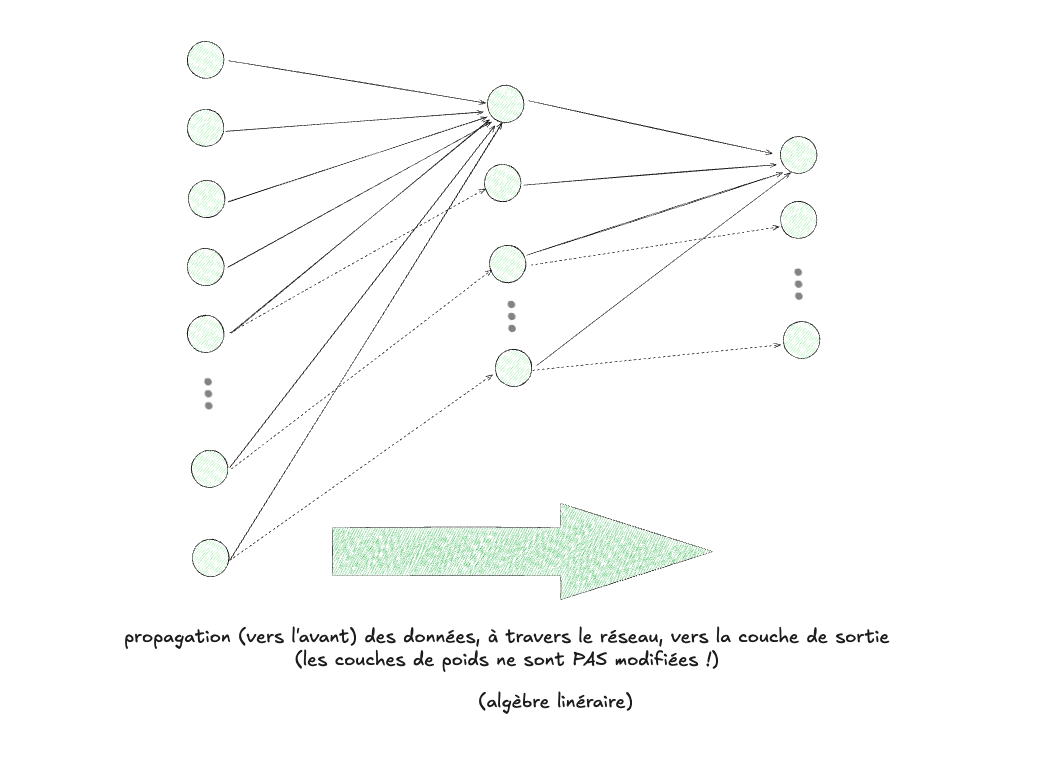
Phase de propagation avant (algèbre linéaire)#
La première phase consiste en la propagation des données à travers le réseau, en passant (de gauche à droite) par toutes les couches successives, pour finir par le calcul des valeurs de sortie. Concrètement, la phase de propagation vers l’avant correspond au calcul de tous les éléments qui constituent le réseau, dans un sens procédural : les données, en tant que vecteurs, sont tout d’abord multipliées à la première couche de poids (une matrice de nombres réels), et ensuite chaque neurone est responsable de faire la somme de ses entrées, et d’appliquer sa fonction d’activation non-linéaire sur le résultat (par exemple une fonction sigmoïde, qui fait en sorte de forcer les valeurs entre 0 et 1). Le processus se répète dans la deuxième section du RDN, avec la seconde couche de poids, pour aboutir aux valeurs pour la couche de sortie. Les poids sont donc utilisés, mais ne sont pas modifiés par ce calcul. On peut donc dire que la phase de propagation est essentiellement une série d’opérations élémentaires d’algèbre linéaire.
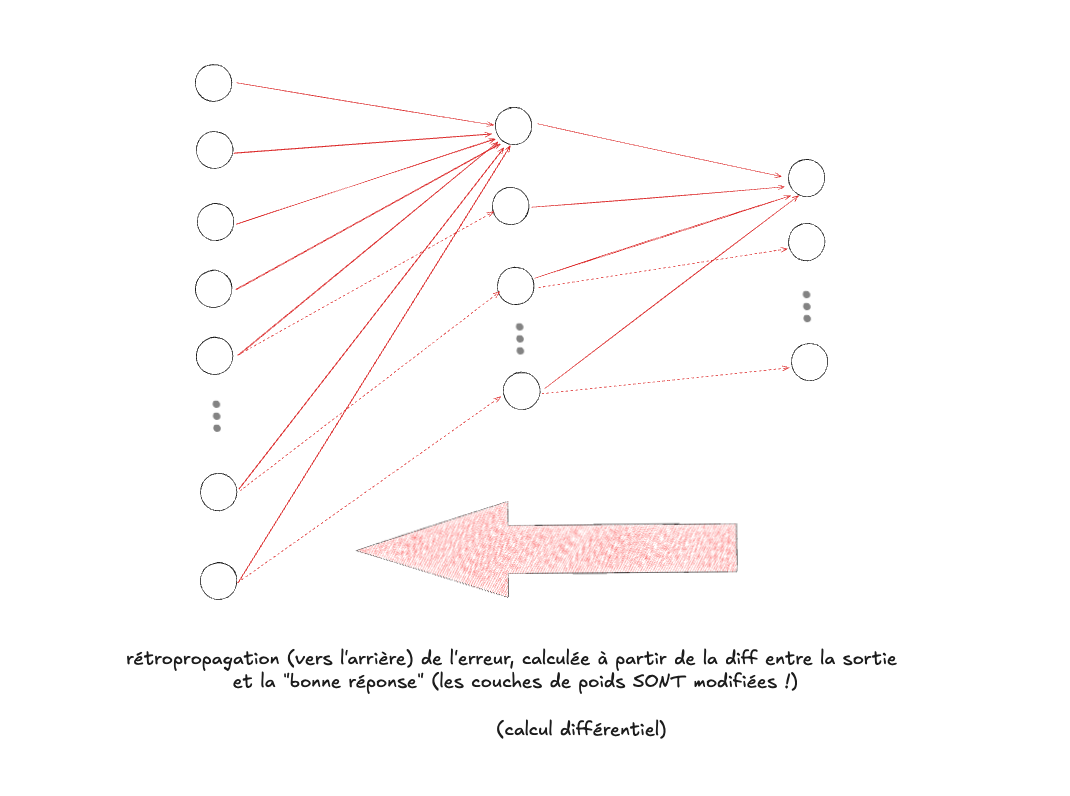
Phase de rétropropagation (calcul différentiel)#
La deuxième phase commence par le calcul de “l’erreur” (c-à-d la différence entre la valeur de sortie calculée par la propagation avant, et la “bonne” valeur, celle qu’on aimerait que le réseau calcule), qui est ensuite rétropropagée vers l’arrière, afin de modifier les couches de poids. L’erreur permet de calculer le gradient, qui est la direction (un vecteur) dans laquelle sa diminution est la plus marquée. Le gradient est utilisé pour faire la modification des poids, qui sont les seuls éléments du réseau modifiés par cette phase (les données elles-mêmes ne sont évidemment pas modifiées). Si la phase de propagation avant est de l’algèbre linéaire, la phase de rétropropagation est donc du calcul différentiel.
Entraînement#
Avant de pouvoir être utilisé, un réseau de neurones doit tout d’abord être entraîné (cette phase est en général coûteuse et complexe, et demande énormément d’ingénierie). L’algorithme de l’entraînement d’un RDN (ou de tout autre algorithme d’AA en fait) peut donc être résumé schématiquement de la manière suivante, en pseudo-code :
Tant que l'erreur (sur les données d’entraînement) est suffisamment élevée :
Propager les données vers l'avant dans le réseau (sans toucher aux poids)
Calculer l'erreur
Rétropropager l'erreur pour modifier les poids du réseauInférence#
Une fois entraîné, un RDN peut être utilisé de manière statique, sans que ses poids ne soient plus jamais modifiés (cette phase est souvent nommée inférence). Seul le mécanisme de propagation avant des données (possiblement avec des nouvelles données, qui n’ont jamais été “vues” par le modèle, sur lesquelles il n’a pas été entraîné donc) intervient donc dans cette phase. Cette phase est en général moins coûteuse computationnellement, mais ceci est de moins en moins vrai, surtout avec les systèmes modernes hyper complexes comme ChatGPT.
Bien que le cerveau biologique n’utilise pas le mécanisme de la rétropropagation en tant que tel (l’analogie est donc assez limitée comme on l’a vu), il est possible qu’il en utilise une forme approximative, mais ceci n’est pas encore totalement élucidé par la neuroscience moderne.
Qu’est-ce que l’apprentissage profond?#
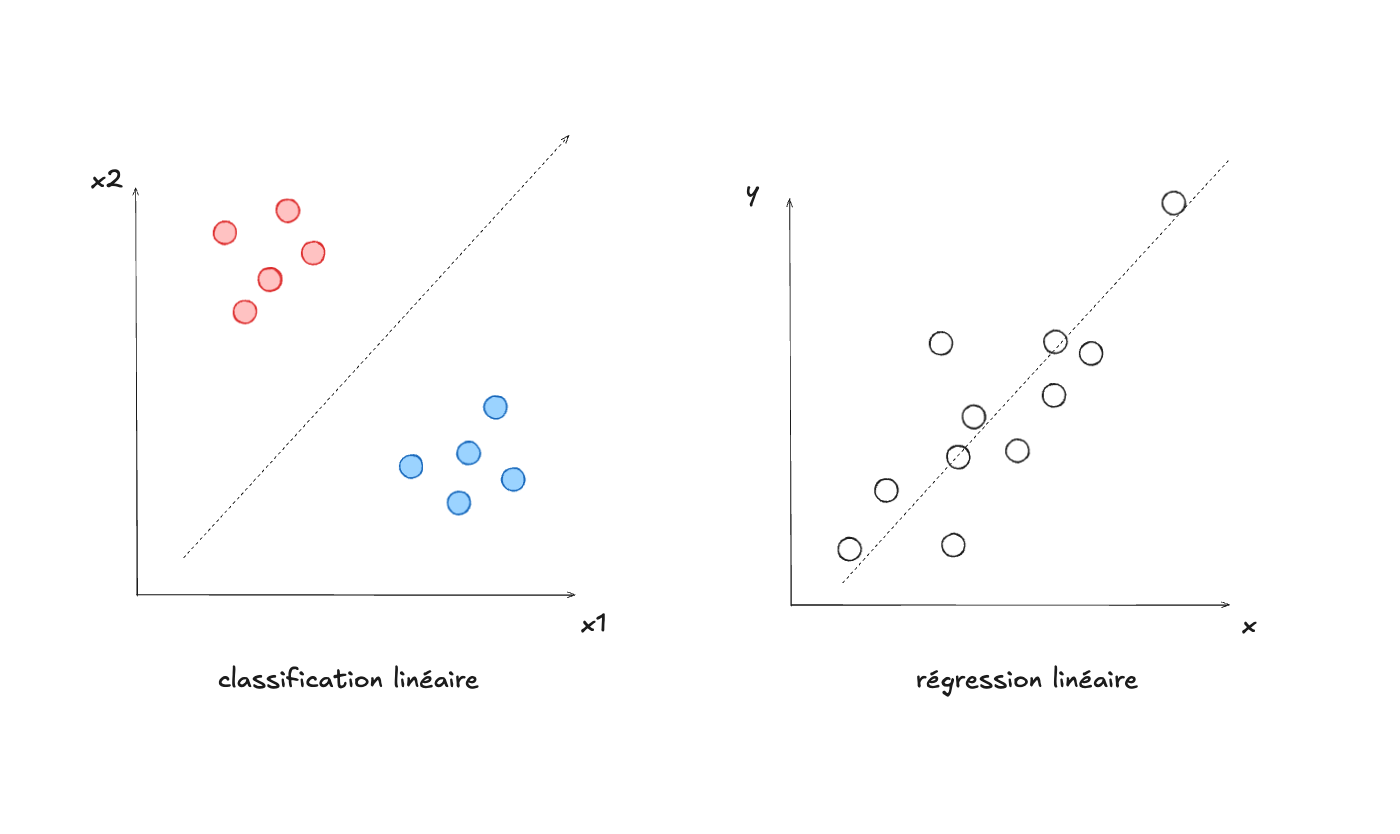
La question de l’apprentissage profond (en anglais deep learning) commence par la différence fondamentale qu’on a observée entre la régression logistique et le réseau de neurones : la couche cachée. À quoi sert-elle? En un mot, à faire en sorte qu’il soit possible d’apprendre des fonctions non-linéaires. Les algorithmes que nous avons vus au module 2 : la régression logistique, la classification naive bayésienne, la régression linéaire, etc. ne permettaient de séparer (classifier) ou modéliser (régression) des données que de manière linéaire.
Par contre il est très facile d’imaginer des problèmes similaires, mais qui sont non-linéaires.
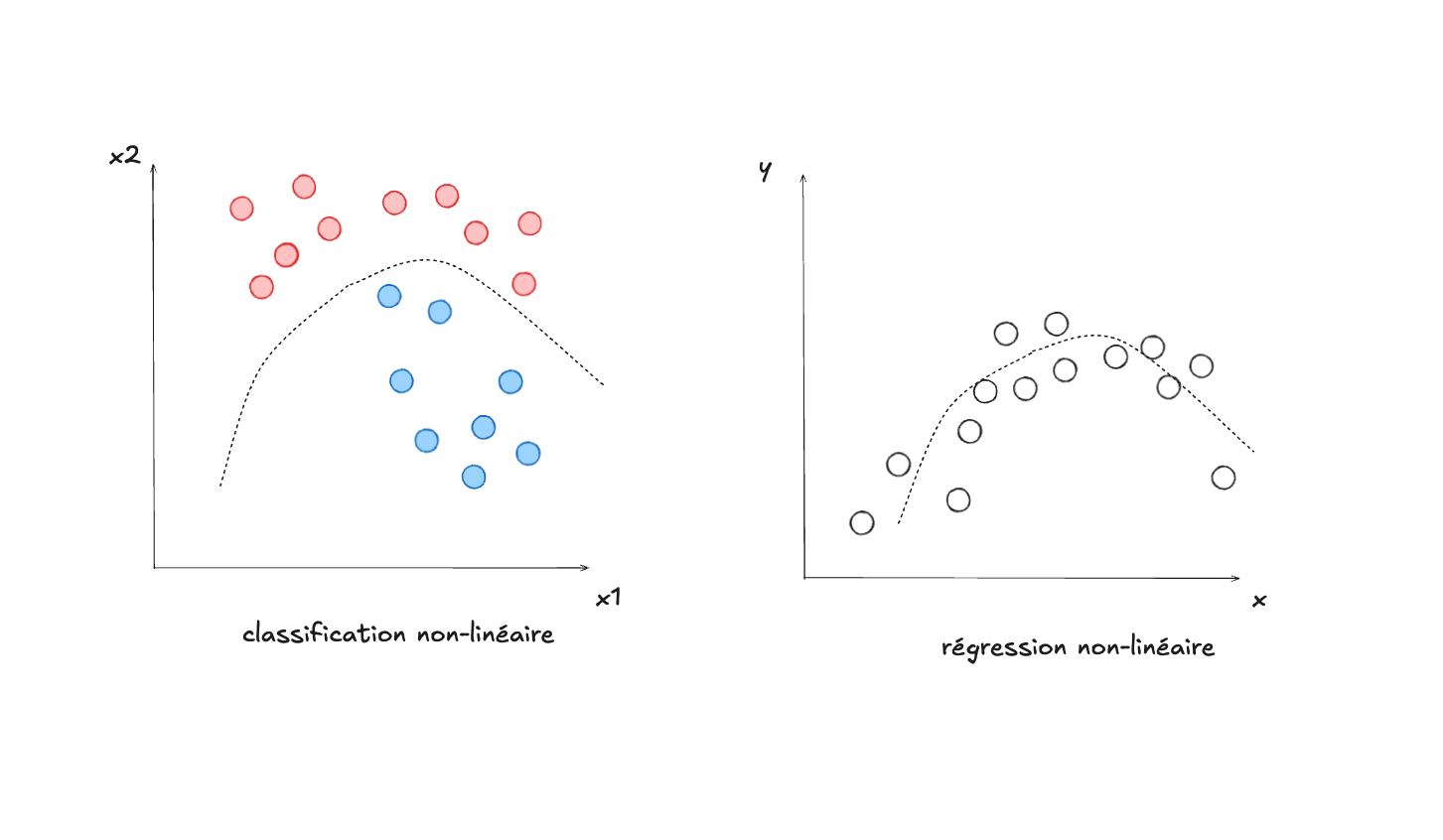
La couche cachée d’un réseau de neurones permet cela, en augmentant les possibilités d’articulation, ou d’expressivité d’un modèle moins puissant, comme la régression logistique. Comment accomplit-elle cela? Essentiellement avec la non-linéarité de la fonction d’activation (sigmoïde par exemple) qu’on retrouve au coeur des neurones de la couche cachée.
Un fin observateur pourrait faire remarquer que la régression logistique utilise elle aussi une fonction sigmoïde, alors qu’on a dit qu’elle était un modèle linéaire.. la différence est que la sigmoïde est seulement utilisée pour transformer le résultat de sa fonction de séparation (linéaire), au moment de la sortie, en probabilité (donc en une valeur entre 0 et 1). Au moment de l’activation, la séparation est déjà accomplie, alors que ce n’est pas le cas pour la couche cachée d’un RDN, avec laquelle il est possible d’effectuer une séparation non-linéaire, en la connectant sur la couche de sortie.
Plus de couches cachées?#
Donc si ajouter une couche cachée augmente la puissance (de linéaire à non-linéaire), qu’arrive-t-il si on en ajoute plusieurs? Est-ce qu’on augmente la puissance encore plus? Est-ce qu’il y a quelque chose au-delà de la non-linéarité?
En fait la réponse est non, le fait d’avoir plus d’une couche cachée n’augmente pas la puissance d’un RDN, et le théorème d’approximation universelle le démontre formellement.
Ceci explique en partie pourquoi la recherche en matière de réseaux de neurones n’a pas exploré cette avenue de manière particulièrement vigoureuse, jusqu’à l’avènement de l’apprentissage profond. Différents problèmes et limitations techniques ont joué un rôle également, comme le “problème du gradient évanescent”, une forme d’instabilité numérique qui fait en sorte que la rétropropagation de l’erreur (du gradient en fait) est rendue de plus en plus difficile à mesure que le réseau acquiert des couches.
En somme, l’apprentissage profond est difficile à résumer, car il est constitué d’une constellation d’idées, d’architectures (pour les réseaux de neurones, aussi appelées des topologies, ou des structures de connectivité) et de progrès techniques (par exemple l’avènement des GPUs, pour accélérer les calculs au niveau physique des processeurs).
La décomposition hiérarchique des connaissances#
Pour comprendre l’intuition la plus fondamentale par rapport à l’apprentissage profond, il faut revenir à l’analogie avec le cerveau et la cognition. Lorsque nous percevons le monde, par exemple à travers la vision, les données brutes qui parviennent à nos yeux sont simplement des variations lumineuses projetées sur la rétine. Ces signaux sont ensuite traités dans le cerveau à travers une succession d’étapes hiérarchiques : les premiers neurones réagissent à des motifs simples (bords, contrastes, orientations), puis des couches plus profondes combinent ces motifs pour former des représentations plus complexes (formes, textures, objets spécifiques). À un niveau encore plus élevé, ces représentations se combinent pour donner lieu à des concepts abstraits, comme reconnaître un visage, une émotion ou même une idée.
De la même manière, un réseau de neurones artificiels profond fonctionne en superposant plusieurs couches cachées : les premières extraient des caractéristiques élémentaires des données, les suivantes en composent des motifs plus riches, et ainsi de suite jusqu’à atteindre des niveaux d’abstraction qui permettent de résoudre des tâches complexes (par exemple comprendre une phrase, traduire un texte ou générer une image). Ce traitement en couches successives est précisément ce qui confère à l’apprentissage profond son nom et sa puissance : la capacité de transformer des données brutes en représentations de plus en plus élaborées, utiles pour la prise de décision ou la production de contenu.
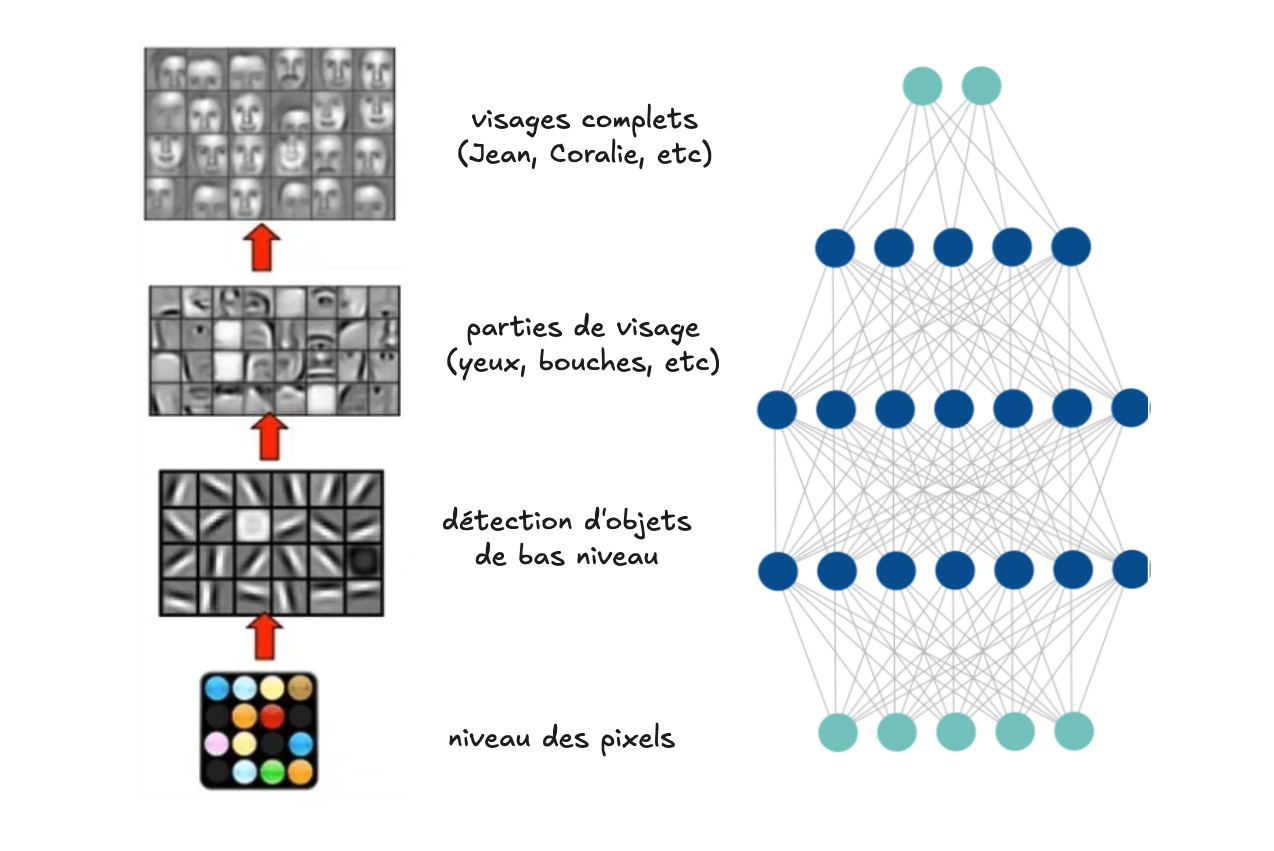
Des caractéristiques “manuelles” à une représentation riche et entièrement dérivée par le RDN#
Avant l’essor de l’apprentissage profond, la plupart des algorithmes d’apprentissage automatique reposaient sur des caractéristiques (en anglais features) construites “à la main”, souvent de manière ad hoc. En pratique, cela signifiait que les experts du domaine devaient analyser les données brutes (images, textes, sons, etc.) et en extraire eux-mêmes les éléments jugés pertinents : par exemple, dans une image, on pouvait calculer des contours, des textures ou des histogrammes de couleur ; dans du texte, on pouvait compter les fréquences de mots ou utiliser des règles grammaticales prédéfinies. L’efficacité du modèle d’apprentissage dépendait donc en grande partie de la qualité de ce travail manuel de conception des features.
Le changement de paradigme apporté par les réseaux de neurones profonds consiste à laisser le modèle apprendre directement ces représentations, au lieu de les définir à priori. Grâce à leurs multiples couches cachées, les RDN peuvent automatiquement dériver des caractéristiques de plus en plus abstraites à partir des données brutes. Par exemple, un réseau de vision artificielle apprend d’abord à détecter des bords, puis des formes, puis des objets entiers, sans que l’humain ait besoin de coder explicitement ces étapes.
Ce passage des features manuelles à des représentations apprises est ce qui a permis aux réseaux de neurones modernes d’atteindre une telle puissance : le modèle n’est plus limité par l’intuition ou les connaissances préalables des humains, mais peut découvrir, dans les données elles-mêmes, les structures les plus utiles pour accomplir une tâche donnée.
L’essor des processeurs graphiques (GPUs)#
Un autre facteur déterminant dans l’essor de l’apprentissage profond a été l’utilisation des processeurs graphiques (GPUs). Initialement conçus pour accélérer le rendu des images dans les jeux vidéo, les GPUs se sont révélés idéaux pour les calculs massivement parallèles nécessaires à l’entraînement des réseaux de neurones. Là où un processeur classique (CPU) excelle dans l’exécution séquentielle de tâches diverses, un GPU est capable de réaliser en parallèle des milliers d’opérations mathématiques identiques, comme des multiplications de matrices. Cette capacité a permis de réduire drastiquement les temps d’entraînement, rendant possible l’exploration de modèles beaucoup plus grands et complexes qu’auparavant.
Un second progrès technique essentiel a été l’apparition de frameworks de différentiation automatique (comme Theano à l’époque, suivi par TensorFlow, PyTorch et d’autres). Ces bibliothèques ont démocratisé l’usage de la rétropropagation du gradient en automatisant le calcul des dérivées partielles à travers des réseaux de neurones potentiellement très profonds. Avant cela, implémenter la rétropropagation à la main pour chaque nouveau modèle était fastidieux et sujet aux erreurs. Grâce à ces outils, les chercheurs et praticiens ont pu se concentrer sur la conception d’architectures et d’applications, tout en profitant d’une optimisation fiable et efficace en arrière-plan. Ce mariage entre puissance matérielle (GPUs) et outils logiciels (différentiation automatique) a véritablement ouvert la voie à l’ère moderne de l’apprentissage profond.