Un mini ChatGPT dans Google Sheets (travail noté 4) #
Un modèle de langage est un outil mathématique qui permet de modéliser la distribution statistique des mots : en présence (ou dans le contexte) de certains mots, quel mot a tendance à suivre, et dans quelle proportion des cas (c’est-à-dire avec quelle probabilité). Un modèle de langage n’est pas un objet abstrait qui décrit une réalité théorique : il s’agit d’un modèle statistique entraîné sur des données particulières. De la même manière qu’un modèle de prédiction de la température pour la ville de Montréal est différent d’un modèle pour la ville de Québec, un modèle de langage créé par exemple à partir des données de 100 livres écrits au 19e siècle, et un autre à partir de 100 livres écrits au 20e siècle, seront deux modèles distincts, et auront des propriétés statistiques très différentes.
Le modèle du travail noté du module 2 était un modèle de classification, dont le fonctionnement implicite (“sous le capot”) était en fait un modèle génératif, “inversé” comme nous l’avons vu à l’aide du théorème de Bayes. Le modèle que nous allons construire ici sera explicitement génératif. Notre modèle sera un modèle bigramme, qui calcule la probabilité d’un mot étant donné le mot qui le précède :
$$P(\mathtt{mot\ à\ prédire} \mid \mathtt{mot\ qui\ précède})$$La barre verticale dans la notation signifie “étant donné”, ou “en présence de”, ou “dans le contexte de”, ce qui, mathématiquement, correspond à une probabilité conditionnelle.
La tâche de notre modèle de classification pour les courriels était de discriminer (répondre oui ou non à la question : est-ce un pourriel?) tandis que la tâche de notre modèle bigramme sera ici de générer du nouveau texte, une fois le modèle entraîné, en faisant de l’échantillonnage. La génération se fera un mot à la fois, en choisissant à chaque fois le mot suivant, de manière aléatoire, selon la distribution de probabilité conditionnée sur le mot précédent (pour faire une analogie, c’est comme si nous utilisions à chaque fois un dé spécialisé, avec autant de faces qu’il y a de mots dans le vocabulaire, et chacune biaisée de manière spécifique en fonction du mot précédent, ce qui est représenté dans le diagramme qui suit avec les petites enclumes, pour dénoter les différents poids) :
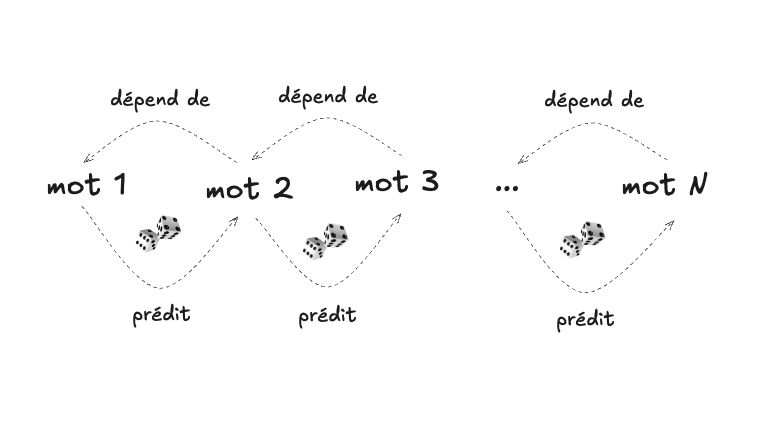
La génération de nouveau texte à l’aide de l’échantillonnage est précisément ce qui permet à ChatGPT de répondre à une question, ou de composer un poème.
Consignes #
Suivez les instructions ci-haut pour construire tout d’abord le fichier Google Sheets avec toutes les données nécessaires.
Une fois qu’il est complété et fonctionnel, partagez votre fichier et copier le lien vers celui-ci dans un document PDF (Attention : aucun autre format que PDF ne sera accepté).
Répondez aux questions d’interprétation qui suivent dans le même fichier PDF, en fournissant des réponses claires et précises.
Entraînement du modèle #
Voyons maintenant comment il est possible de calculer ces probabilités en entraînant un modèle bigramme génératif à partir d’un texte très simple.
Étant donné que nous allons encore une fois utiliser la tableur en ligne Google Sheets, assurez-vous tout d’abord que votre version est correctement configurée.
Copiez tout d’abord les mots de ce texte dans la colonne A d’une nouvelle
“feuille” Google Sheets, un mot par rangée (assurez-vous d’utiliser correctement
la fonction “copier-coller”, si vous le faites) :
le
chat
dort
le
chien
mange
le
chat
mange
une
souris
le
chien
dort
la
souris
court
la
souris
mange
le
fromage
le
chat
court
le
chien
voit
le
chat
le
chat
voit
la
souris
le
chien
court
Notez tout d’abord que la colonne A (son contenu) est très souvent nommée le
“corpus d’entraînement”. Il s’agit du texte brut à partir duquel nous allons
calculer (ou entraîner) les paramètres du modèle. Pour les vrais modèles de
langage, ce texte peut être extrêmement volumineux !
(Il peut comprendre des millions de livres, par exemple).
Dans la première cellule de la colonne B (donc B1), entrez maintenant cette
formule :
=A2
La colonne B devrait être étendue jusqu’à la cellule B37, en double-cliquant
sur le petit “+” qui apparaît quand votre curseur est placé au-dessus du coin
inférieur droit de la cellule B1 (il est possible que Google Sheets offre de
le faire pour vous, automatiquement).
Dans la cellule C1, entrez maintenant cette formule :
=A1 & " " & B1
Encore une fois, la colonne C doit s’étendre jusqu’à la cellule C37. À ce stade,
votre feuille devrait ressembler à ceci :
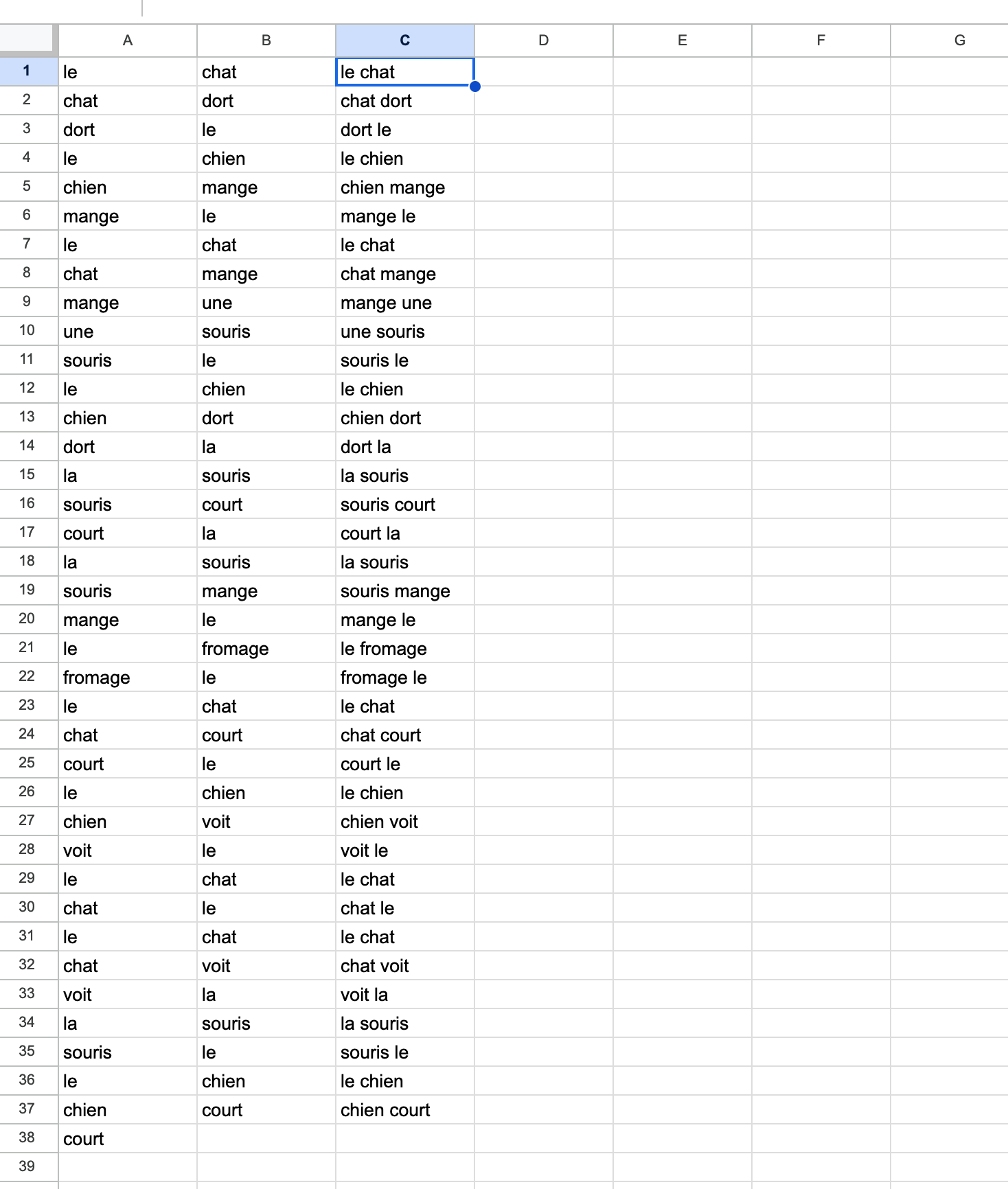
À ce stade, il devrait être clair pour vous que la colonne C contient tous les
bigrammes (séquences de deux mots consécutifs) extraits du texte de la colonne
A (notez que la colonne B n’est qu’un mécanisme intermédiaire pour les obtenir
facilement).
Nous allons maintenant compter, dans la colonne D, le nombre de fois où un
bigramme particulier apparaît dans le corpus d’entraînement de la colonne A
(la colonne D doit être étendue pour avoir le même nombre d’éléments que la
colonne C) :
=COUNTIF(C:C, C1)
Si vous obtenez une erreur avec la formule à ce stade, il est très possible que les paramètres linguistiques de votre Google Sheets ne soient pas correctement configurés.
On constate par exemple que le bigramme le chien apparaît 4 fois, tandis que
le bigramme fromage le, apparaît seulement une fois.
Dans la colonne E, nous allons maintenant calculer les paramètres de notre
modèle, soit la probabilité d’un mot, étant donné le mot qui le précède (ce qui
constitue donc un modèle qui génère des mots):
Pour ce faire, entrez dans la cellule E1 (la formule est un peu complexifiée par
le fait qu’on veut considérer tous les mots de la colonne A sauf le dernier, car
sa présence fausserait légèrement les probabilités) :
=D1 / COUNTIF(A$1:INDEX(A:A, COUNTA(A:A)-1), A1)
La probabilité d’un mot étant donné le mot qui le précède est donc simplement le
nombre de fois où ce bigramme particulier apparaît dans le texte, divisé par le
nombre de fois où le premier mot du bigramme apparaît (le dénominateur est
nécessairement plus grand ou égal que le numérateur, prenez un moment pour vous
en convaincre). Étant donné que cette valeur est une probabilité, elle doit
nécessairement être contenue entre 0 et 1. Le colonne E doit s’étendre jusqu’à
E37.
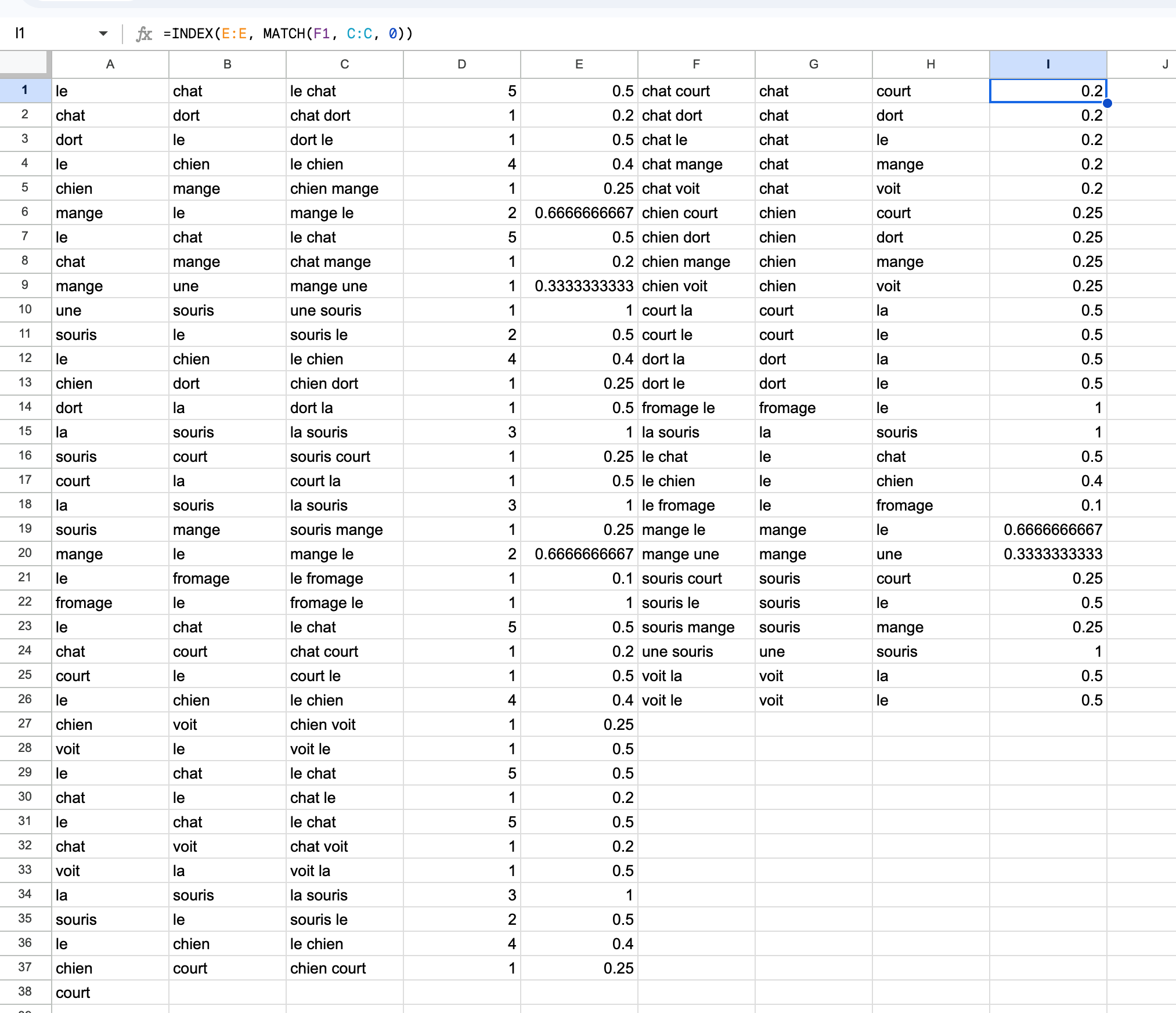
Dans la colonne F nous allons filtrer la colonne C (tous les bigrammes, qui
comprennent donc des bigrammes répétés) pour ne retenir que les bigrammes
uniques (cette colonne devrait avoir 26 éléments) :
=SORT(UNIQUE(C:C))
Nous devons ensuite séparer les mots des bigrammes uniques, les premiers mots
dans la colonne G :
=INDEX(SPLIT(F1, " "), 1)
suivis des deuxièmes mots (des bigrammes uniques de la colonne F) dans la
colonne H :
=INDEX(SPLIT(F1, " "), 2)
Et dans la colonne I nous allons ajouter les probabilités correspondantes
(provenant de la colonne E):
=INDEX(E:E, MATCH(F1, C:C, 0))
On peut maintenant constater que le mot souris suit nécessairement (avec
certitude, soit une probabilité de 1) le mot la, tandis que le mot le peut
être suivi des mots chat, chien et fromage avec des probabilités de 0.5,
0.4 et 0.1, respectivement.
À ce stade, votre feuille devrait ressembler à ceci :
Utilisation du modèle (inférence) #
Maintenant que notre modèle de langage est “entraîné” (c’est-à-dire que les probabilités pour les différents bigrammes, les paramètres donc, sont calculées), on peut l’utiliser pour générer, avec l’échantillonnage, un nouveau texte, aléatoire, probablement différent donc du corpus d’entraînement.
Pour démarrer le mécanisme de génération, on peut entrer un premier mot dans la
cellule J1, par exemple le mot le (ce mot doit faire partie du vocabulaire du
modèle).
Ensuite, la génération peut être effectuée de manière itérative avec cette
formule plus complexe, à partir de la cellule K1 si vous désirez que les mots
soient générés à la verticale, ou J2 si vous désirez qu’ils le soient à
l’horizontale.
=LET(
next_word_mask, ARRAYFORMULA($G:$G = J1),
next_words, FILTER($H:$H, next_word_mask),
probs, FILTER($I:$I, next_word_mask),
probs_cumul, SCAN(0, probs, LAMBDA(a, b, a + b)),
sampled_word_idx, MATCH(RAND(), {0; probs_cumul}, 1),
INDEX(next_words, sampled_word_idx)
)
Étant donné que cette formule contient plusieurs lignes elle doit être entrée dans l’espace de la formule, en haut des colonnes.
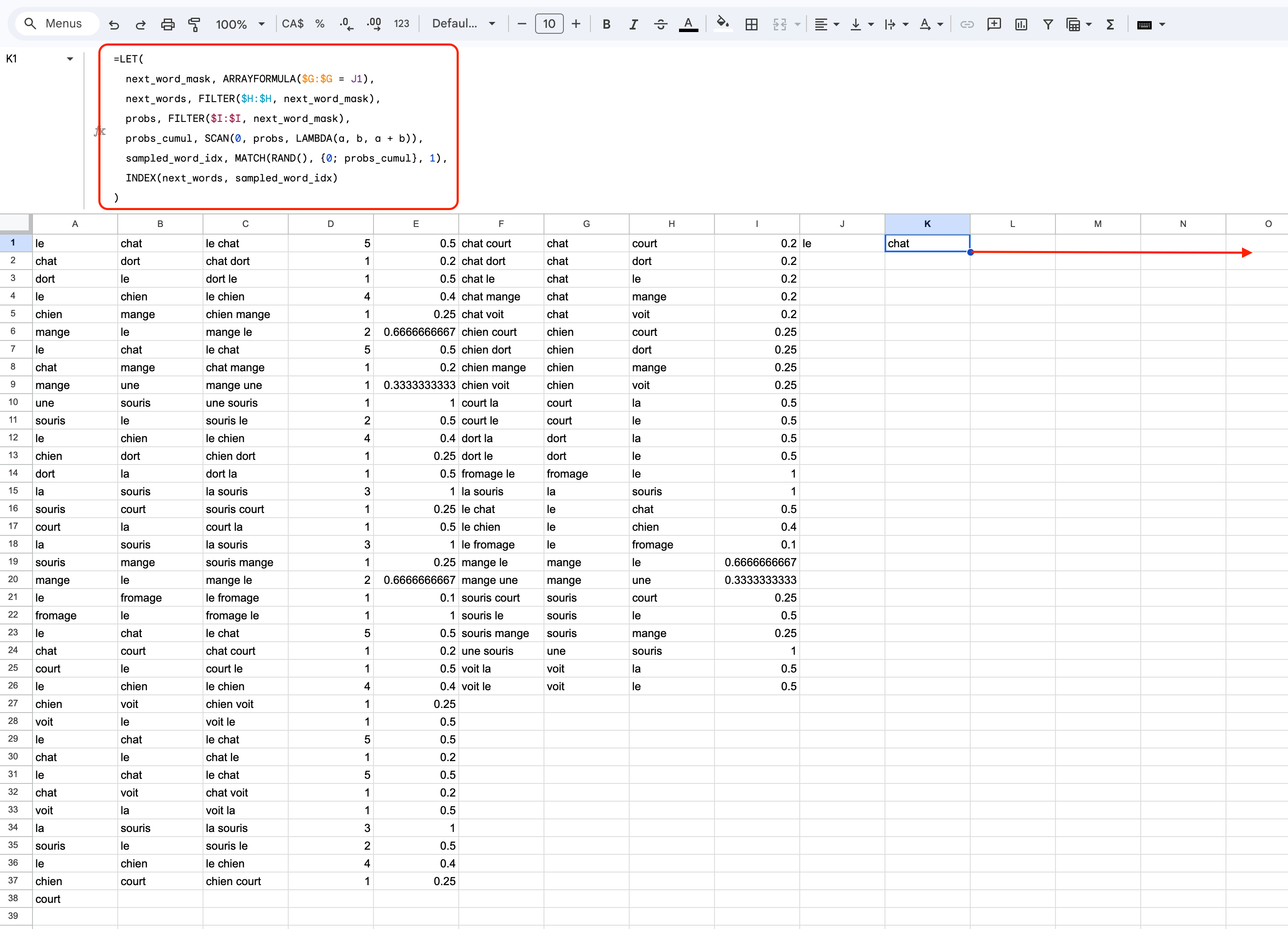
Cette formule détermine tout d’abord quels sont les prochains mots possibles
(suivant le mot de départ le que nous avons choisi, dans ce cas particulier),
ainsi que leur probabilité associée. Elle détermine ensuite le mot suivant en
choisissant un nombre aléatoire qui est utilisé en tant qu’index dans la liste
des probabilités cumulatives (cette procédure est appelée échantillonnage).
Si votre deuxième mot généré se trouve dans la cellule K2, vous pouvez
continuer la génération en glissant la cellule vers la droite. Si votre deuxième
mot se trouve plutôt dans la cellule J2, vous pouvez poursuivre la génération
en glissant la cellule J2 vers le bas.
Questions #
Quels sont les paramètres du modèle (quelles colonnes exactement)?
Expliquez en vos mots comment ces paramètres sont calculés.
En quoi la colonne
Bde ce modèle diffère de la colonneBdu modèle de classification des courriels du travail noté 2?Expliquez en quoi le modèle de classification du travail 2 était un modèle discriminatif, alors que ce modèle de langage est un modèle génératif?
Quelle est la conséquence du fait que le bigramme
le chatapparaisse 5 fois dans le corpus d’entraînement (colonneA)?Quelle est la conséquence du fait que le bigramme
la sourisapparaisse 3 fois, et en quoi cela diffère du bigramme de la question (5)?Est-ce que la présence de certains bigrammes fait en sorte qu’il est possible de générer des séquences moins grammaticales? Lesquels en particulier?
Est-ce que la présence de certains bigrammes fait en sorte qu’il est possible de générer des séquences sémantiquement plus étranges? Lesquels en particulier?
De quel type d’apprentissage s’agit-il ici : supervisé, non-supervisé ou semi-supervisé? Expliquez en quoi ça l’est.
Si on utilisait un modèle trigramme au lieu d’un bigramme, qu’est-ce qui changerait? Quelles seraient les contraintes entraînées par l’utilisation d’un modèle trigramme au lieu d’un modèle bigramme?
Supposons que le modèle ait généré le mot
voit, expliquez la conséquence que le choix du prochain mot (celui suivant immédiatementvoit) va avoir sur la suite de la phrase générée.Est-ce qu’il y a une limite à la longueur de la phrase pouvant être générée par le modèle?
Est-ce qu’il est possible que le modèle génère un bigramme qui ne fait pas partie des exemples qui ont servis à son entraînement?
Expliquez quelles sont les limites au niveau de la capacité de généralisation de ce modèle. À quoi sont dues ces limites?
Expliquez comment on pourrait faire en sorte que le modèle puisse modéliser et générer des phrases complètes (avec une majuscule et un point final).